1 ОСНОВЫ ПРОЕКТИРОВАНИЯ ЭЛЕКТРОННЫХ УСТРОЙСТВ НА ПЛИС
1.1 СПЕЦИАЛИЗИРОВАННЫЕ ИНТЕГРАЛЬНЫЕ СХЕМЫ
Стремясь к достижению высоких технических характеристик и потребительских качеств своей продукции, разработчики электронных устройств используют специализированные ИС (СПИС). Их применение обеспечивает следующие преимущества:
— уменьшение габаритов устройства. Применение СПИС позволяет снизить количество ИС, уменьшить размеры печатных плат и тем самым сократить габариты всего устройства;
— повышение технических характеристик. Уменьшение количества ИС приводит к повышению системного быстродействия и сокращению потребляемой мощности;
— повышение надежности. Так как вероятность ошибки или поломки устройства прямо пропорциональна количеству ИС, надежность устройств, использующих СПИС, значительно возрастает;
— обеспечение защиты разработки. Так как скопировать устройство, содержащее СПИС, значительно сложнее (а иногда практически невозможно), чем устройство на стандартных компонентах, применение СПИС позволяет обеспечить авторские права разработчика;
— повышение гибкости модификации. Так как модификация СПИС не требует, как правило, переработки остальных узлов, переразводки печатных плат и т.д., возможности отладки и модификации устройства значительно повышаются.
1.2 КЛАССИФИКАЦИЯ СПИС
В большинстве случаев в литературе выделяют следующие классы СПИС (ASIC) [3]:
— программируемые пользователем ИС – ПЛИС (PLD).
— масочно-программируемые ИС – базовые матричные кристаллы (БМК) или вентильные матрицы (Gate Arrays).
— ИС на стандартных ячейках (Standard Cells).
— полностью заказные ИС (Full Custom).
ПЛИС и БМК относятся к категории полузаказных ИС, поскольку внутрисхемная топология частично формируется при производстве самих ИС, а частично программируется в соответствии с требованиями потребителя. Остальные СПИС являются заказными, т.к. вся топология схемы с учетом требуемых функций разрабатывается при производстве кристаллов.
Классификация СПИС приведена на рис.1.
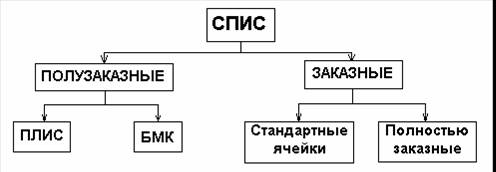
Рис.1. Классификация СПИС
1.3 ПЛИС
Программируемые логические интегральные схемы – ПЛИС являются одними из самых перспективных элементов цифровой схемотехники. ПЛИС представляет собой кристалл, на котором расположено большое количество простых логических элементов. Изначально эти элементы не соединены между собой. Соединение элементов (превращение разрозненных элементов в электрическую схему) осуществляется с помощью электронных ключей, расположенных в этом же кристалле. Электронные ключи управляются специальной памятью, в ячейки которой заносится код конфигурации цифровой схемы. Таким образом, записав в память ПЛИС определенные коды, можно собрать цифровое устройство любой степени сложности (это зависит от количества элементов на кристалле и параметров ПЛИС). В отличие от микропроцессоров, в ПЛИС можно организовать алгоритмы цифровой обработки на аппаратном (схемном) уровне. При этом быстродействие цифровой обработки резко возрастает. Достоинствами технологии проектирования устройств на основе ПЛИС являются:
- минимальное время разработки схемы (нужно лишь занести в память ПЛИС конфигурационный код);
- в отличие от обычных элементов цифровой схемотехники здесь отпадает необходимость в разработке и изготовлении сложных печатных плат;
- быстрое преобразование одной конфигурации цифровой схемы в другую (замена кода конфигурации схемы в памяти);
- для создания устройств на основе ПЛИС не требуется сложное технологическое производство. ПЛИС конфигурируется с помощью персонального компьютера на столе разработчика. Потому иногда эту технологию называют «фабрикой на столе».
Типичные области применения ПЛИС: цифровая обработка сигналов, пользовательская электроника, системы сбора данных, системы управления, телекоммуникационное оборудование, оборудование для систем беспроводной связи, компьютерное оборудование общего назначения.
1.4 ПЛИС типа FPGA фирмы Xilinx
В настоящее время выпускаются следующие серии ПЛИС FPGA:
- Серия Virtex
- Серия Spartan
- Серия ХС4000
- Серия ХС5200
- Серия ХС3000
ПЛИС типа FPGA фирмы Xilinx выполненны по SRAM кМОП технологии. Характеризуются высокой гибкостью структуры и изобилием на кристалле триггеров. При этом логика реализуется посредством так называемых LUT — таблиц (Look Up Table) Xilinx, а внутренние межсоединения — посредством разветвлённой иерархии металлических линий, коммутируемых специальными быстродействующими транзисторами.
Отличительными системными особенностями являются:
- внутренние буфера с возможностью переключения в высокоомное состояние и тем самым позволяющие организовать системные двунаправленные шины
- индивидуальный контроль высокоомного состояния и времени нарастания фронта выходного сигнала по каждому внешнему выводу
- наличие общего сброса/установки всех триггеров ПЛИС
- множество глобальных линий с низкими задержками распространения сигнала
- наличие внутреннего распределённого ОЗУ Xilinx, реализующегося посредством тех же LUT — таблиц (серии Spartan, Virtex, XC4000).
- наличие внутреннего блочного ОЗУ, один блок имеет ёмкость 4 кбит (семейства Virtex, Virtex-E, Spartan-II, Spartan-IIE) или 18 кбит (семейства Virtex-II и Virtex-IIPro), всего блоков до 556 на кристалл
- наличие встроенных блоков умножителей 18х18 (семейства Virtex-II и Virtex-IIPro), всего блоков до 556 на кристалл
- наличие встроенных блоков процессоров PowerPC-405 (семейство Virtex-IIPro), до 4 процессоров на кристалл
- наличие высокоскоростных трансиверов(семейство Virtex-IIPro), до 24 со скоростью передачи данных 3.125 ГБит/с каждый
Процесс конфигурации
Конфигурационная последовательность (bitstream) может быть загружена в прибор непосредственно в системе и перегружена неограниченное число раз. Инициализация ПЛИС производится автоматически (из загрузочного ПЗУ Xilinx) при подаче напряжения питания или принудительно по специальному сигналу. В зависимости от ёмкости ПЛИС процесс инициализации занимает от 20 до 900 мс, в течение которых выводы ПЛИС находятся в высокоомном состоянии (подтянуты к логической единице).
Потребление энергии
Статическое потребление энергии достаточно мало и для некоторых серий составляет единицы микроватт. Динамическое же потребление пропорционально возрастает с частотой функционирования проекта и зависит от степени заполнения кристалла, характера логической структуры проекта на кристалле, параметров режима внешних выводов ПЛИС и т. д.
Корпуса
Для каждого отдельно взятого семейства ПЛИС Xilinx существует преемственность кристаллов по типу корпуса и, соответственно, цоколёвке, то есть в одни и те же корпуса упаковываются ПЛИС различного логического объёма. Например, в корпусе PQ/HQ240 имеются ПЛИС с ёмкостью от 13тыс. (XC4013XLA) до 85 тыс. вентилей (XC4085XLA), что позволяет разработчику, задавшись на этапе проектирования печатной платы определённым типом корпуса, в дальнейшем устанавливать ПЛИС наиболее подходящего размера.
1.5 ПЛИС Actel — основа при реализации «SoC» бортовой аппаратуры
Сегодня в России, как и во всем мире, подходы к созданию электронных устройств и систем, работающих в тяжелых условиях эксплуатации, существенно меняются. Основная тенденция — переориентация на специализированные изделия с сокращенным циклом проектирования и производства, что позволяет достигать максимальной эффективности при выполнении конкретных задач управления, контроля и сбора информации.
На передний план выходит концепция построения «системы на кристалле» (System on Chip — SoC). Наиболее серьёзное препятствие для ее реализации — это, безусловно, высокая стоимость изготовления СБИС такого типа. Их разработка, отладка и освоение производства требуют значительных затрат, поэтому ощутимый экономический эффект можно получить только при выпуске больших партий этих изделий — как правило в сотни тысяч устройств. Однако сегодня для построения «системы на кристалле» появилась экономически эффективная альтернатива СБИС — программируемые логические интегральные схемы (ПЛИС). Новые поколения этих микросхем способны конкурировать со СБИС как по числу вентилей, быстродействию и надежности, так и по функциональности. Более того, сейчас на рынок выпущены матрицы, не требующие внешних средств для хранения и загрузки конфигурации и готовые к работе с момента подачи питания, что до сих пор считалось исключительным преимуществом СБИС.
Внедрение концепции «системы на кристалле» признано одним из приоритетных направлений развития отечественной электроники, определяющим, по сути, технологию построения будущих поколений бортовой аппаратуры. «Система на кристалле» имеет три принципиальные особенности: o в одной микросхеме технологической платформы (как правило, СБИС или ПЛИС сверхвысокой степени интеграции) реализован функционально законченный набор модулей управления и обработки данных;
— встроенный микропроцессор ориентирован преимущественно на выполнение задач управления, а не обработки данных;
— поток данных в системе организован непосредственно между контроллерами, а не через микропроцессорную шину.
Среди основных достоинств правильно спроектированной «системы на кристалле» следует вьщелить максимальную эффективность в решении прикладных задач. Это обусловлено глубокой оптимизацией внутренней структуры и отсутствием избыточности, характерной для систем, построенных на основе универсальных компонентов. А высокая оптимизация определяет высокую экономическую эффективность подобных решений как за счет прямой экономии (снижение числа компонент на плате, уменьшение площади печатной платы и пр.), так и за счет косвенной экономии (меньшего энергопотребления, повышения надежности, производительности, уменьшения объема аппаратной отладки и пр.).
Реализованная на базе высоконадежной и высокоскоростной ПЛИС «система на кристалле» помимо всех достоинств, присущих решениям на основе СБИС, имеет важные дополнительные преимущества:
— значительное сокращение расходов на изготовление микросхем и экономический эффект при реализации проектов малой и средней серийности (до десятков тысяч штук);
— существенное сокращение сроков выпуска новых изделий на рынок (time to market);
— гибкая конфигурируемость системы в соответствии с текущими нуждами конкретного проекта и задачами упрощения модификации; — повышенная надежность изделия благодаря 100%-ному тестированию производителем регулярной структуры платформы;
— возможность высокоэффективной внутрикристальной отладки;
— возможность прототипирования изделий для особых условий эксплуатации на основе функционально идентичных, но более дешевых коммерческих исполнений платформы.
Один из самых успешных разработчиков и производителей в области новых технологий ПЛИС высокой надежности, используемых в тяжелых условиях эксплуатации, — Actel Corp. (www.actel.ru), специализирующаяся с 1985 года на производстве ПЛИС как для военных и авиационно-космических приложений, так и для нужд промышленности и потребительского рынка. Компания прочно занимает место в первой тройке мировых производителей ПЛИС общего назначения и уже много лет лидирует на рынке радиационно стойких ПЛИС, выпуская до 80% мирового объема этих изделий для бортового оборудования космических аппаратов. Actel непрерывно вкладывает значительные средства в совершенствование своих технологий. Наивысшие приоритеты развития сегодня — это надежность, которая всегда отличала продукцию корпорации, и обеспечение комплексной интеграции цифровой электроники на одном кристалле ПЛИС.
Сегодня Actel предлагает три основные группы изделий:
— многократно программируемые ПЛИС на основе Flash-технологии;
— однократно программируемые ПЛИС на основе технологии прожигаемых перемычек (Antifuse);
— радиационно стойкие ПЛИС с уникальными характеристиками на основе технологии Antifuse.
Как однократно, так и многократно программируемые ПЛИС компании Actel последних поколений благодаря своей уникальной архитектуре и функциональности, приближенной к СБИС, а также высоким показателям надежности идеально подходят для построения «систем на кристалле».
Основное отличие ПЛИС компании от традиционных матриц на основе ячеек СОЗУ — это способ хранения конфигурации. Элементы памяти (перемычки в семействах Antifuse и флэш-ключи в семействах Flash) ПЛИС Actel распределены по всей площади кристалла и являются одновременно ключами, задающими конфигурацию. Такое технологическое решение позволяет избавиться от потенциально ненадежной коммутационной матрицы (ГКМ) на основе ячеек СОЗУ, не защищенных от высокоэнергетических частиц, воздействующих на электронные устройства даже на уровне моря, а также отказаться от всех элементов, участвующих в процессе загрузки конфигурации. На сегодняшний день аналогов этой технологии нет.
Рассмотрим современные семейства ПЛИС, предлагаемые компанией Actel. Новые семейства однократно программируемых ПЛИС, выполненных по технологии Antifuse, характеризуются следующими особенностями:
— рекордной надежностью — FIT, или число отказов/сбоев на 109 ч наработки не более 10;
— чрезвычайно низким энергопотреблением;
— большой логической емкостью — до 4 млн. системных вентилей*;
— рекордной системной производительностью — свыше 500 МГц;
— отсутствием процесса загрузки конфигурации и готовностью к работе с момента подачи питания;
— защищенностью от воздействия высокоэнергетических частиц (даже у коммерческих изделий) — свыше 60 МэВ/см2 и высокой радиационной стойкостью — накопленная доза (TID) более 300 крад;
— отсутствием возможности несанкционированного считывания конфигурации — конфигурация защищена технологией FuseLock, при запуске нет конфигурационной последовательности (bit-stream);
— доступом специализированного логического анализатора к любому элементу работающей схемы без затрат трассировочных ресурсов самой ПЛИС;
— широким выбором поддерживаемых стандартов ввода-вывода -LVDS, HSTL1, SSTL2/3, GTL+, LVTTL, LVCMOS, LVPECL;
— полной совместимостью по корпусам изделий различной емкости и в различном исполнении: от коммерческих до выполненных в соответствии со стандартом MIL-STO-883B и радиационно стойких;
— высокой экономической эффективностью.
ПЛИС, выполненные по технологии Antifuse, объединяют в себе достоинства традиционной программируемой логики и базовых матричных кристаллов (БМК) и позволяют потребителю производить БМК непосредственно «у себя на столе». Но неопытных разработчиков иногда отпугивают трудности применения однократно программируемых матриц, которые невозможно проектировать по популярному циклическому маршруту «написал-прошил-посмотрел». Для подобного стиля работы Actel предлагает многократно программируемые матрицы. При этом следует отметить, что все изделия Actel изначально ориентированы на применение классического маршрута проектирования СБИС на языках описания оборудования высокого уровня (HDL).
Выпускаемые компанией Actel многократно программируемые матрицы на основе Flash-технологии имеют следующие достоинства:
— возможность перепрограммирования непосредственно в системе (ISP);
— логическая емкость до 1 млн. системных вентилей*;
— малое энергопотребление;
— высокая системная производительность — до 350 МГц;
— готовность к работе с момента подачи питания — отсутствует процесс загрузки конфигурации;
— высокая радиационная стойкость — накопленная доза до 100 крад и устойчивость к воздействию высокоэнертегических частиц свыше 60 МэВ/см2 (для микросхем в исполнении MIL-STD-883B);
— отсутствие возможности несанкционированного считывания конфигурации — конфигурация защищается технологией FlashLock, конфигурационная последовательность при запуске отсутствует;
— богатый выбор поддерживаемых стандартов ввода-вывода;
— полная совместимость по корпусам изделий различной емкости и в различном исполнении.
К выпуску готовится новое поколение многократно программируемых ПЛИС емкостью до 3 млн. системных вентилей с улучшенной архитектурой ячейки, расширенным набором интерфейсов ввода-вывода и с блоками флэш-памяти для хранения программ или данных микропроцессоров, встроенных в «систему на кристалле».
Современный маршрут проектирования интегральных систем состоит из трех основных этапов: ввода (описания) проекта, его синтеза в выбранном базисе и, наконец, трассировки и размещения на кристалле. Неотъемлемая часть маршрута проектирования — комплексная верификация дизайна с помощью средств симуляции после каждого из основных его этапов: до синтеза, после синтеза и после размещения на кристалле. Если спецификация проекта (включая построение testbench) разработана с должным качеством и последовательно реализована в RTL, можно практически полностью выявить и устранить ошибки дизайна еще до программирования кристалла. Такой подход, конечно, выдвигает высокие требования к организации проектной группы и самодисциплины всех ее инженеров и менеджеров. Однако результаты работы, выраженные в качестве конечного изделия, безусловно, окупают организационные затраты. Поскольку проекты разработки «систем на кристалле» по своей сложности значительно превосходят «обычные» проекты создания связующих логических схем на ПЛИС, роль средств управления группой разработчиков становится не менее важной, чем роль комплексов программных средств разработки ПЛИС и СБИС (EDA), например FPGA Advantage фирмы Mentor Graphics.
Коротко рассмотрим основные требования к организации проектного менеджмента при создании систем на кристалле. Современная система управления разработкой, построенная в соответствии с требованиями международных стандартов качества ISO, должна пердусматривать проведение проектных форумов для обсуждения технических деталей проекта в режиме реального времени. Кроме того, в нее должны входить подсистемы отладки проектов (issue tracking), хранения исходных данных проекта (knowledge base), контроля версий (version control) и планирования для прогноза сроков выполнения этапов проекта и оперативной корректировки планов. При этом значительно возрастают требования к руководителю проекта, который должен оперативно управлять работой группы в реальном времени.
Одна из компаний, успешно разрабатывающих системные решения на основе новых поколений ПЛИС высокой интеграции фирмы Actel, — петербургское СКБ Интегральных Систем (www.asicdesign.ru), имеющее статус официального технического центра Actel в России.
На платформе ПЛИС ProASICplus в СКВ ИС создан комплекс программно-аппаратных решений СнК186 для построения бортовых регистраторов высокоскоростных данных.
Структура устройства, представляющего собой бортовой управляющий вычислительный комплекс (БУВК) автономного робота с подсистемой сбора и хранения потоковых данных (160 Мбит/с), реализована на одной печатной плате с «системой на кристалле» на основе ПЛИС APA750-PQ208I емкостью 750 тыс. системных вентилей. В состав системы входят: процессорное ядро Турбо186, контроллер USB 2.0 с производительностью 480 Мбит/с, контроллер IDE ATA5 для внешнего накопителя, контроллер телеметрической информации и аппаратный компрессор данных «без потерь». Плата с потреблением около 1 Вт и габаритами 100×200 мм позволила заменить громоздкий бортовой промышленный компьютер, существенно улучшив эксплуатационные характеристики и параметр FIT системы в целом. Очевидно, что подобные решения находят применение в большом числе бортовых приложений в самых различных областях, где важны габариты и энергопотребление устройства, а к надежности системы предъявляются повышенные требования. Благодаря широкому применению технологии «система на кристалле» на основе оптимальной платформы ПЛИС такие решения позволят выйти на новый технологический уровень и будут способствовать
1.6 КЛАССИФИКАЦИЯ ПЛИС
Микросхемы, программируемые пользователями, открыли новую страницу в истории современной микроэлектроники и вычислительной техники. Они сделали БИС/СБИС, предназначенные для решения специализированных задач, стандартной продукцией электронной промышленности со всеми вытекающими из этого положительными следствиями: массовое производство, снижение стоимости микросхем, сроков разработки и выхода на рынок продукции на их основе. ПЛИС можно классифицировать по многим признакам, в первую очередь:
— по уровню интеграции и связанной с ним логической сложности;
— по архитектуре (типу функциональных блоков, характеру системы межсоединений);
— по числу допустимых циклов программирования;
— по типу памяти конфигурации («теневой»памяти );
— по степени зависимости задержек сигналов от путей их распространения;
— по системным свойствам;
— по схемотехнологии (КМОП, ТТЛШ и др.);
— по однородности или гибридности (по признаку наличия или отсутствия в микросхеме областей с различными по методам проектирования схемами, такими как ПЛИС, БМК, схемы на стандартных ячейках).
Все перечисленные признаки имеют значение и отображают ту или иную сторону возможных классификаций. Выделяя основные признаки и укрупняя их, рассмотрим классификацию по трем, в том числе двум комплексным, признакам:
— по архитектуре;
— по уровню интеграции и однородности/гибридности;
— по числу допустимых циклов программирования и связанному с этим типу памяти конфигурации.
В классификации по первому признаку (рис. 2, а) ПЛИС разделены на 4 класса.
Первый из классов — SPLD, Simple Programmable Logic Devices, т. е. простые программируемые логические устройства. По архитектуре эти ПЛИС делятся на подклассы программируемых логических матриц ПЛМ (PLA, Programmable Logic Arrays) и программируемой матричной логики ПМЛ (PAL, Programmable Arrays Logic, или GAL, Generic Array Logic).
Оба эти подкласса микросхем реализуют дизъюнктивные нормальные формы (ДНФ) переключательных функций, а их основными блоками являются две матрицы: матрица элементов И и матрица элементов ИЛИ, включенные последовательно. Такова структурная модель ПЛМ и ПМЛ. Технически они могут быть выполнены и как последовательность двух матриц элементов ИЛИ-НЕ, но варианты с последовательностью матриц И-ИЛИ и с последовательностью матриц ИЛИ-НЕ — ИЛИ-НЕ функционально эквивалентны, т. к. второй вариант согласно правилу де Моргана тоже реализует ДНФ, но для инверсных значений переменных.
На входы первой матрицы поступают n входных переменных в виде как прямых, так и инверсных значений, так что матрица имеет 2n входных линий. Таким образом, отпадает необходимость специально инвертировать входные переменные и на промежуточных шинах можно реализовать любую конъюнкцию входных переменных и их инверсий, а также переменных обратных связей. На выходах матрицы И формируются конъюнктивные термы, ранг которых не выше n. В дальнейшем для краткости конъюнктивные термы называются просто термами.
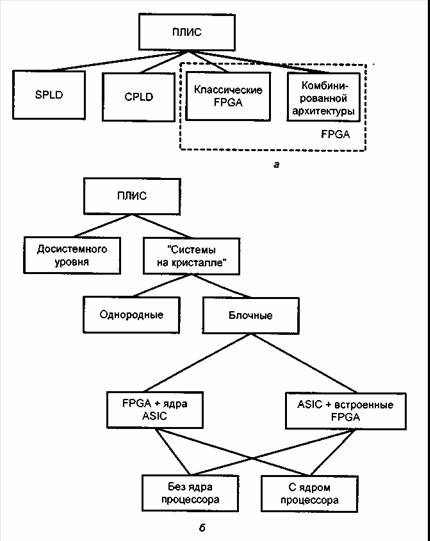
Рис.2. Классификация ПЛИС (а — поархитектуре, б – по уровню интеграции)
Выработанные термы поступают на вход матрицы ИЛИ. Эти матрицы для ПЛМ и ПМЛ различны. В ПЛМ матрица ИЛИ программируется, а в ПМЛ она фиксирована.
Программируемая матрица ИЛИ микросхем ПЛМ составлена из дизъюнкторов, имеющих по q входов. На входы каждого дизъюнктора при программировании можно подать любую комбинацию имеющихся термов, причем термы можно использовать многократно (т. е. один и тот же терм может быть использован для подачи на входы нескольких дизъюнкторов).
Число дизъюнкторов в матрице ИЛИ определяет число выходов ПЛМ. Из изложенного видно, что ПЛМ позволяет реализовать систему из m переключательных функций, зависящих не более чем от n переменных и содержащих не более чем q термов.
В ПМЛ выработанные матрицей И термы поступают на фиксированную (непрограммируемую) матрицу элементов ИЛИ. Это означает жесткое заранее заданное распределение имеющихся термов между отдельными дизъюнкторами.
ПЛМ обладают большей функциональной гибкостью, все воспроизводимые ими функции могут быть комбинациями любого числа термов, формируемых матрицей И. Это полезно при реализации систем переключательных функций, имеющих большие взаимные пересечения по термам. Такие системы свойственны, например, задачам формирования сигналов управления машинными циклами процессоров. Для широко распространенных в практике задач построения «произвольной логики» большое пересечение функций по термам не типично. Для них программируемость матрицы ИЛИ используется мало и становится излишней роскошью, неоправданно усложняющей микросхему. Поэтому микросхемы ПМЛ распространены больше, чем ПЛМ, и к их числу относится большинство SPLD. Обобщённая структура «классической» ПМЛ представлена на рис.3.
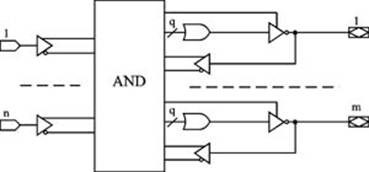
Рис.3. Обобщённая структура «классической» ПМЛ
«Классические» ПМЛ также позволяют программировать высокоимпедансное (третье) состояние выходного буфера, что делает возможным двунаправленный вывод использовать как вход. Кроме того, индивидуальное управление с помощью отдельного терма третьим состоянием выходного буфера позволяет двунаправленный вывод в один момент времени использовать как выход, а в другой момент — как вход или отключать от внешней шины, например, для уменьшения нагрузки.
Возможность ПМЛ передачи значения выходного сигнала по цепи обратной связи на вход матрицы И позволяет в одном устройстве строить многоуровневые каскадные схемы. Однако следует избегать случаев, когда значение некоторой функции является аргументом этой же функции, так как в подобной ситуации схема перестаёт быть комбинационной и переходит в класс последовательностных схем, а отсутствие в циклах элементов задержки приводит к непредсказуемости поведения схемы.
Обобщенная структура универсальных ПМЛ (рис.4.) включает n входов, программируемую матрицу И, m выходных макроячеек (MC) с одной обратной связью и m2 макроячеек (MCF) с двумя обратными связями. Архитектура макроячейки с двумя обратными связями показана на рис. 5.
В макроячейках с одной обратной связью отсутствует цепь от входа выходного буфера к входу матрицы И. С каждой макроячейкой универсальных ПМЛ связано различное число промежуточных шин, что позволяет более рационально их использовать: простые функции назначать для реализации на выходы, связанные с небольшим числом промежуточных шин, а сложные — назначать на выходы, связанные с большим числом промежуточных шин. Кроме того, каждая макроячейка допускает программирование логического уровня выходного сигнала благодаря наличию в архитектуре макроячейки вентиля Исключающее ИЛИ с программируемой связью одного входа с «землёй».
Поэтому из двух функций yi или ¯yi для реализации можно выбрать наиболее подходящую (например, которая требует для реализации меньше промежуточных шин), а необходимый вид функции на выходе ПМЛ образуется путём программирования логического уровня выходного сигнала.
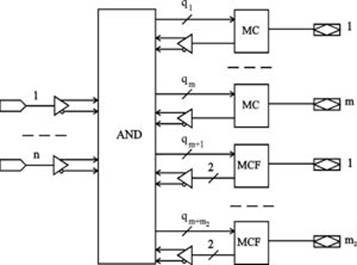
Рис. 4. Обобщённая структура универсальных ПМЛ
Макроячейки с двумя обратными связями допускают одновременное использование в двух целях: для реализации промежуточных функций и для приёма входных переменных.
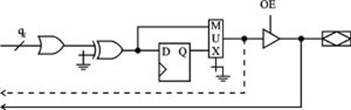
Рис. 5. Обобщённая структура выходной макроячейки
универсальных ПМЛ с двумя обратными связями
1.7 Cложные программируемые логические схемы CPLD (Complex Programmable Logic Devices) (сложные программируемые логические устройства) содержат относительно крупные программируемые логические блоки — макроячейки соединённые с внешними выводами и внутренними шинами. Функциональность CPLD кодируется в энергонезависимой памяти, поэтому нет необходимости их перепрограммировать при включении.
Несколько блоков, подобных ПМЛ, объединяются средствами программируемой коммутационной матрицы (рис.6.). В CPLD могут входить сотни блоков и десятки и сотни тысяч эквивалентных вентилей. Архитектуры CPLD разрабатываются фирмами Altera, Atmel, Lattice Semiconductor, Cypress Semiconductor, Xilinx и др. Воздействуя на программируемые соединения коммутационной матрицы и ПМЛ, входящих в состав CPLD, можно реализовать требуемую схему.
Архитектура функциональных блоков здесь во многом подобна архитектуре универсальных ПМЛ. Отличия заключаются в том, что все выходные макроячейки имеют две обратные связи, а промежуточные шины макроячейкам назначаются с помощью распределителя (allocator). Некоторые макроячейки CPLD не имеют связи с внешним выводом. Такие макроячейки называются скрытыми. Скрытые макроячейки имеют только одну обратную связь.
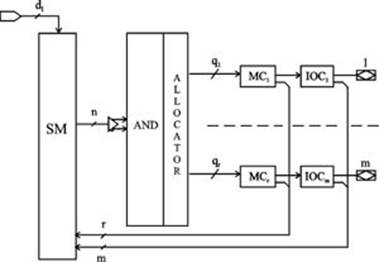
Рис. 6. Обобщённая структура функционального блока CPLD
и его взаимодействие с матрицей переключений
Каждый функциональный блок CPLD будем характеризовать числом входов n; выходных макроячеек m; общим числом макроячеек r, из которых r-m являются скрытыми; суммарным числом промежуточных шин функционального блока q и максимальным числом промежуточных шин qmax, которые могут быть подсоединены к одной макроячейке. Кроме того, общая структура CPLD характеризуется числом E функциональных блоков и числом dI «чистых» входов.
Отметим некоторые особенности синтеза комбинационных схем на CPLD, обусловленные их архитектурными свойствами:
- число подсоединяемых к макроячейке промежуточных шин не фиксировано, как для ПМЛ, а определяется для каждой макроячейки индивидуально;
- в некоторых CPLD промежуточные шины между макроячейками распределяются кластерами и для реализации любой функции (даже очень простой) необходимо не менее qCL промежуточных шин, где qCL — число промежуточных шин в одном кластере;
- для реализации промежуточных функций могут использоваться ресурсы скрытых макроячеек, а также выходных макроячеек, выводы которых используются в качестве входов;
- каждый функциональный блок имеет фиксированное число входов n, по которым могут поступать значения аргументов (в ПМЛ число входов может изменяться за счёт использования двунаправленных выводов в качестве входов);
- общее число аргументов СБФ, реализуемой на CPLD, может быть достаточно большим (dI + m·E – N), в то время как число аргументов СБФ, реализуемой одним функциональным блоком, ограничено параметром n, имеющим значение от 16 до 36;
- все значения аргументов и промежуточных функций поступают на входы функциональных блоков только через матрицу переключений, поэтому при частом дублировании входных переменных различных функциональных блоков возникает опасность быстрого истощения ресурсов матрицы переключений.
В качестве примера можно рассмотреть архитектуру микросхем семейства MAX 7000 фирмы Altera [5].
Архитектура MAX 7000 включает следующие элементы:
- логические блоки (LAB, Logic array blocks)
- макроячейки (МЯ, Macrocells)
- логические расширители, разделяемый и параллельный (Expander product terms)
- программируемая матрица соединений (PIA, Programmable interconnect array)
- блоки управления вводом/выводом (БВВ, I/O control blocks)
В структуру ПЛИС MAX 7000 входят четыре специализированных входа. Эти входы могут быть использованы как входы общего назначения для обработки “быстрых” сигналов. Через эти входы на каждую МЯ могут быть поданы глобальные управляющие сигналы (синхронизация, сброс, переход в третье состояние). На рис.7 представлена функциональная схема ПЛИС.
Архитектура ПЛИС MAX 7000 основана на логических блоках, состоящих из 16 макроячеек. Логические блоки соединяются вместе при помощи программируемой матрицы соединений (PIA).
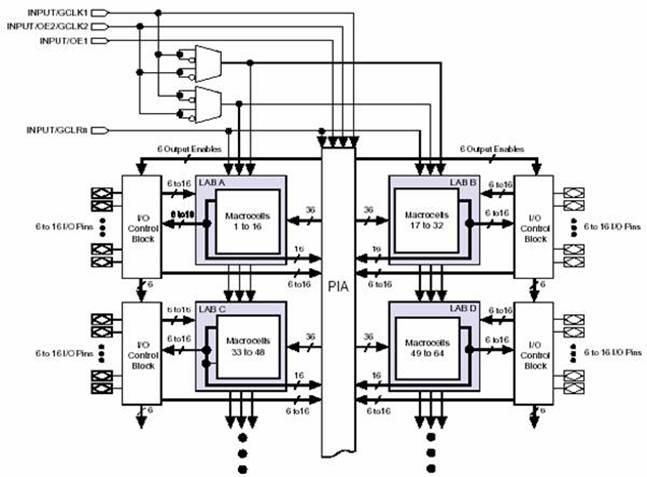
Рис.7 Функциональная схема ПЛИС MAX 7000
К каждому логическому блоку подводятся следующие сигналы:
- 36 сигналов от PIA, используемых в качестве логических входов;
- глобальные управляющие сигналы;
- непосредственные цепи от входных буферов к регистрам, обеспечивающие высокое быстродействие.
Макроячейка содержит три функциональных блока:
- локальная программируемая матрица (Logic Array);
- матрица распределения термов (Product Term Select Matrix);
- программируемый регистр (Programmable register).
На рис.8 приведена структурная схема МЯ. Комбинационная логика реализуется на локальной программируемой матрице, которая передает пять основных термов в матрицу распределения термов. Матрица распределения термов позволяет реализовать комбинационную функцию путем выполнения операций “исключающее или”, “ИЛИ” над логическими произведениями. Кроме этого, матрица распределения может передать термы на регистры.
Для расширения функциональных возможностей доступны две логические схемы:
- разделяемый логический расширитель. Инвертирует терм и передает назад на локальную программируемую матрицу;
- параллельный логический расширитель. Передает термы из предыдущих МЯ в последующие.

Рис.8 Структурная схема макроячейки.
Комбинационная логика реализуется на локальной программируемой матрице, которая передает пять основных термов в матрицу распределения термов. Матрица распределения термов позволяет реализовать комбинационную функцию путем выполнения операций “исключающее или”, “ИЛИ” над логическими произведениями. Кроме этого, матрица распределения может передать термы на регистры.
САПР фирмы Altera способны автоматически оптимизировать процесс распределения термов в соответствии с требованиями проекта.
Для каждого регистра может быть выбран один из трех способов тактирования:
- тактирование глобальным синхросигналом. Это самый быстрый вариант;
- тактирование глобальным сигналом с применением локального сигнала разрешения тактирования;
- тактирование сигналом от локальной программируемой матрицы.
В MAX7000доступны два глобальных тактовых сигнала выводы GCLK1 или GCLK2.
Для каждого регистра имеется возможность асинхронного сброса и установки. Матрица распределения термов обеспечивает управление этими операциями. Возможно индивидуальное управление сбросом каждого регистра при помощи глобального тактирующего сигнала GCLRn.
Хотя большинство логических функций могут быть реализованы пятью термами, доступными в каждой МЯ. Возможна ситуация, при которой пяти переменных будет недостаточно. Для решения подобной проблемы предназначен специальный механизм – логические расширители. Этот механизм позволяет использовать термы любых МЯ, находящихся в данном логическом блоке. Логические расширители помогают добиться максимального быстродействия при минимальных затратах.
Каждый логический блок содержит 16 разделяемых расширителей, которые могут быть рассмотрены как емкость неподключенных термов (один от каждой макроячейки). Терм инвертируется и возвращается обратно в локальную программируемую матрицу. Инвертированный терм может использоваться любой МЯ данного логического блока. Временная задержка, вызванная использованием расширителя обозначается TSEXP.
Схема расширителя изображена на рис.9
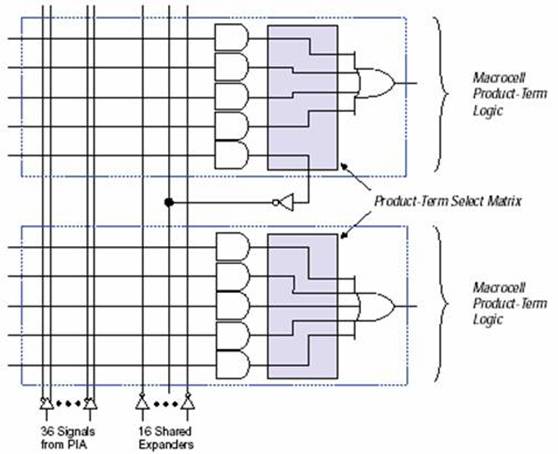
Рис.9 Разделяемый расширитель
Расширитель реализует логические функции, состоящие из термов соседних МЯ. Таким образом, МЯ связываются в цепочку. Расширитель позволяет использовать до 20 термов. Пять термов берутся непосредственно из данной МЯ, остальные 15 из соседних МЯ данного логического блока. Дополнительная временная задержка, вносимая расширителем, обозначается tPEXP. Последовательно в цепочку можно соединить до 8 МЯ. Схема параллельного логического расширителя представлена на рис.10.
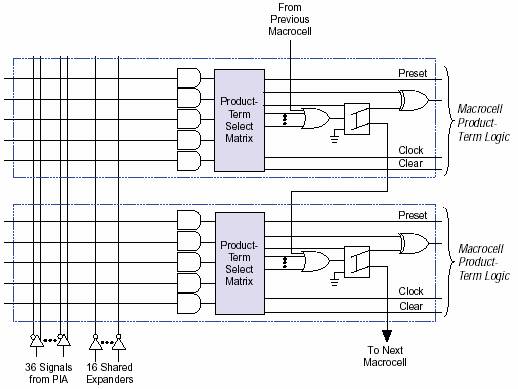
Рис.10 Параллельный расширитель
Программируемая матрица соединений (PIA) реализует все внутренние связи. С этой шиной соединены все источники и приемники сигналов. Все специальные сигналы, выводы ввода/вывода, сигналы МЯ. На рис.11 показано как сигналы PIA подводятся к логическим блокам (LAB).
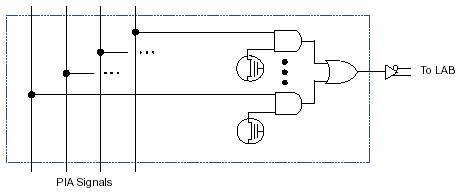
Рис.11 Схема передачи сигналов из программируемой матрицы
соединений в логические блоки.
Блок управления вводом/выводом позволяет индивидуально конфигурировать каждый вывод ПЛИС. Вывод ПЛИС может быть настроен на ввод, вывод, двунаправленную передачу данных. Все выводы ПЛИС могут быть выводами буфера с третьим состоянием, который может управляться глобальным сигналом. Кроме того, возможен режим работы с открытым коллектором. На рис.6 показана схема блока управления.
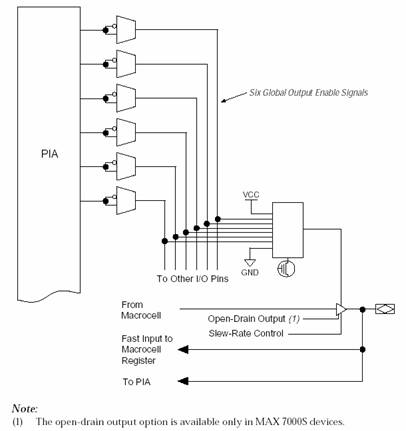
Рис.12 Блок управления вводом/выводом
ПЛИС семейства MAX 7000 соответствуют промышленному стандарту 4-pin Joint Test Action Group (JTAG) IEEE Std. 1149.1-1990). Программирование в системе. (In-System Programmability ISP) быстро и эффективно позволяет изменять конфигурацию ПЛИС как в стадии тестирования проекта, как и в течение эксплуатации. Перепрограммирование может быть выполнено непосредственно в системе, для этого необходим только один уровень напряжения 5В. Пока идет программирование, выводы микросхемы переводятся в третье состояние, для избежания конфликта с системой. Сопротивление внутренних “подтягивающих” резисторов 50кОм.
Для программирования используется специальный загрузочный кабель Altera MasterBlaster, ByteBlaster или ByteBlasterMV. Программирование ПЛИС в системе позволяет снизить вероятность повреждения при эксплуатации устройства. Кроме того, модернизация устройства может быть выполнена в полевых условиях, например, с помощью модема.
Для программирования ПЛИС во встраиваемых приложениях может быть использован Jam Standard Test and Programming Language (STAPL)
ПЛИС MAX 7000 могут работать в режиме энергосбережения. Этот режим позволяет сократить энергозатраты на 50% и более. Большинство логических функций не используют значительную часть вентилей – этот факт используется для реализации данного режима.
Разработчик может для каждой МЯ выбрать режим высокого быстродействия или энергосбережения (устанавливается или снимается TurboBit). МЯ, работающие в режиме экономии электроэнергии, характеризуются дополнительной временной задержкой tLPA, задержка добавляется к параметрам tLAD, tLAC, tIC, tEN, tSEXP, tACL, tCPPW.
Большинство ПЛИС семейства MAX 7000 поддерживают интерфейс MultiVolt I/O, который обеспечивает работу микросхемы в устройствах с разным уровнем питания. На выводы VCCINT всегда должно быть подано напряжение 5В. При уровне напряжения на выводе VCCINT 5В порог входного напряжения соответствует уровню 5В, однако совместим и с логикой 3,3 В.
На выводы VCCIO может быть подано напряжение питания 3,3В или 5В, в зависимости от требований к выходному каскаду. Когда на выводы VCCIO подано напряжение 5В, уровень выходного каскада соответствует системам 5В. Если подано 3,3В, выходной сигнал соответствует логике 3,3 В, однако совместим и с 5В.
Выводы ПЛИС MAX 7000 могут быть настроены как выводы с открытым коллектором.
Для выходных буферов ПЛИС существует возможность регулирования уровня шумов. Низкий уровень шумов может быть достигнут за счет снижения быстродействия. И наоборот, повышение быстродействия приводит к росту уровня шума. Это достигается посредством настроек Slew Rate Control.
Все микросхемы серии MAX 7000 содержат программируемый бит секретности, который контролирует доступ к “зашитым” в микросхему данным. Если этот бит установлен, прошивка не может быть считана. Такой способ обеспечивает высокую степень защищенности проекта, т.к. информация, находящаяся в ячейках EEPROM, не видима. Бит защиты может быть сброшен только при перепрограммировании ПЛИС.
1.8 Микросхемы программируемых пользователями вентильных матриц FPGA (Field Programmable Gate Arrays)
Содержат блоки умножения — суммирования (DSP), которые широко применяются при обработке сигналов, а также логические элементы (как правило на базе таблиц перекодировки (таблиц истинности)) и их блоки коммутации. FPGA обычно используются для обработки сигналов, имеют больше логических элементов и более гибкую архитектуру, чем CPLD. Программа для FPGA хранится в распределённой памяти, которая может быть выполнена как на основе энергозависимых ячеек статического ОЗУ (подобные микросхемы производят, например, фирмы Xilinx и Altera) — в этом случае программа не сохраняется при исчезновении электропитания микросхемы, так и на основе энергонезависимых ячеек Flash-памяти или перемычек antifuse (такие микросхемы производит фирма Actel и Lattice Semiconductor) — в этих случаях программа сохраняется при исчезновении электропитания. Если программа хранится в энергозависимой памяти, то при каждом включении питания микросхемы необходимо заново конфигурировать её при помощи начального загрузчика, который может быть встроен и в саму FPGA. Альтернативой ПЛИС FPGA являются более медленные цифровые процессоры обработки сигналов. FPGA применяются также, как ускорители универсальных процессоров в суперкомпьютерах (например: Cray -XD1, SGI — Проект RASC).
В своей основе состоят из большого числа конфигурируемых логических блоков (ЛБ), расположенных по строкам и столбцам в виде матрицы, и трассировочных ресурсов, обеспечивающих их межсоединения.
В архитектуре FPGA явно прослеживается большое сходство с архитектурой MPGA. Разница в том, что FPGA, поступающая в распоряжение потребителя, имеет уже готовые, стандартные, хотя и не запрограммированные, трассировочные ресурсы, не зависящие от конкретного потребителя. Получение конкретного проекта на базе FPGA, как и на основе других ПЛИС, реализуется воздействием на программируемые межсоединения, в ходе которого обеспечивается замкнутое состояние одних участков и разомкнутое — других. Обращаться к изготовителю FPGA при этом не требуется.
Архитектуры FPGA разрабатываются фирмами Xilinx, Actel, Altera, Atmel, Agere Systems (ранее Lucent Technologies), QuickLogic и др. В качестве примера можно рассмотреть архитектуру микросхем семейства Flex 10K фирмы Altera [5].
Фирма Altera пошла по пути развития FPGA-архитектур и предложила в семействе FLEX10K так называемую двухуровневую архитектуру матрицы соединений (рис. 13). Глобальная матрица соединений представлена группами горизонтальных и вертикальных соединений, реализующих межблочные связи (FastTrack межсоединения — непрерывная структура, обеспечивающая быстрые и предсказуемые задержки). Возможна эмуляция третьего состояния, позволяющая реализовывать внутренние шины с третьем состоянием. Кроме того, по этим каналам мпередается до шести общих тактовых сигналов и четыре общих сигнала сброс.
На рисунке представлены блоки элементов ввода/вывода (I/O Elements), логические блоки (LAB) и блоки встроенной памяти (EAB). Внутри логических блоков связи между логическими элементами (LE) реализуются с помощью локальной программируемой матрицы соединений. СБИС данного семейства имеют в целом сходную внутреннюю архитектуру, в основе которой лежит логический элемент.
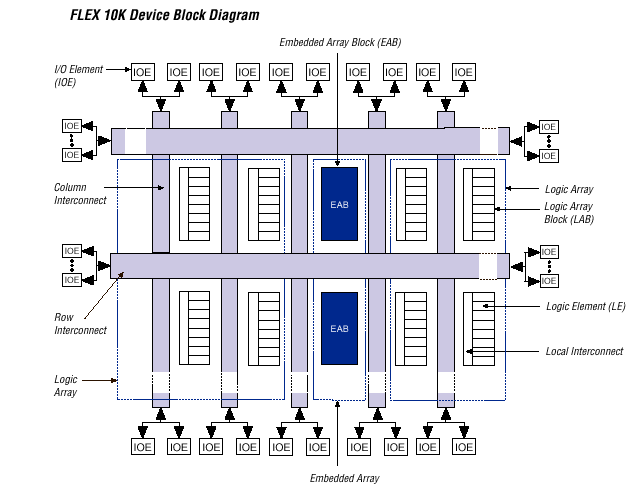
Рис.13 Блок схема ПЛИС FLEX10K
LE содержит четырехвходовую таблицу перекодировок (LUT), обеспечивающую реализацию логических функций, синхронный триггер и некоторую дополнительную логику (рис.14).
Цепи переноса (Carry-In и Carry-Out) позволяют быстро выполнять арифметические функции сложения, счета и сравнения (автоматически используются программным обеспечением и мегафункциями) (рис.15). Цепи каскадирования (Cascade-In и Cascade-Out) позволяют реализовывать высокоскоростные логические функции И или ИЛИ с большим количеством переменных (автоматически используются программным обеспечением и мегафункциями (рис.16).
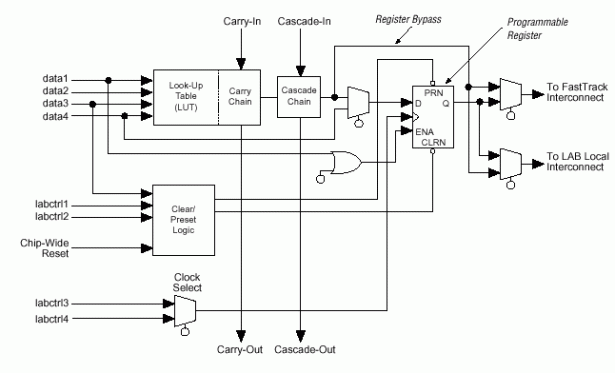
Рис.14 Функциональная схема LE
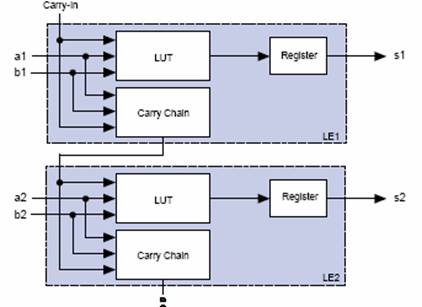
Рис.15 Цепи переноса Carry-In и Carry-Out)
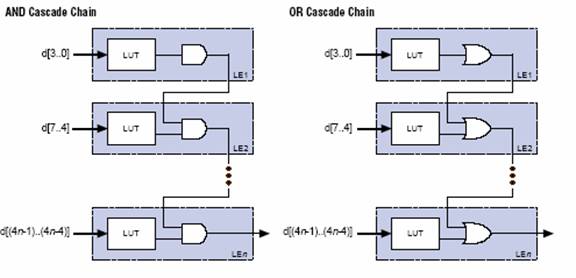
Рис.16 Цепи каскадирования Cascade-In и Cascade-Out
LE объединяются в группы — логические блоки (LAB). Каждый из блоков содержит восемь LE (рис.17). Внутри логических блоков LE соединяются посредством локальной программируемой матрицы соединений, позволяющей соединять любой LE с любым.
Логические блоки связаны между собой и с элементами ввода/вывода посредством глобальной программируемой матрицы соединений. Локальная и глобальная матрицы соединений имеют непрерывную структуру, где для каждого соединения выделяется непрерывный канал.
Двухуровневая архитектура и использование непрерывной структуры соединений на каждом уровне иерархии обеспечивают:
- высокое быстродействие реализуемых устройств;
- возможность точного предсказания задержки распространения сигналов;
- высокую скорость автоматической разводки СБИС;
- возможность размещения выводов СБИС в соответствии с требованиями разработчика.
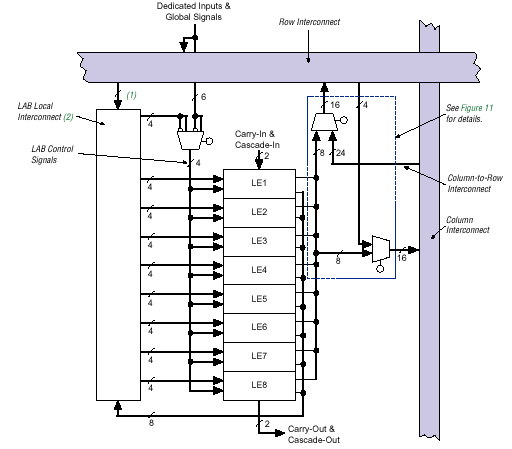
Рис. 17 Организация логического блока
Каждый элемент ввода-вывода содержит: триггеры, позволяющие реализовать временное хранение принимаемого и передаваемого бит данных; буфер, работающий в режимах: ввод, вывод, двунаправленный, выход с открытым коллектором, и обеспечивающий возможность управления его скоростью переключения (рис.18).
Программируемая скорость изменения фронта выходного сигнала позволяет уменьшать шумы при переключении. Кроме того, микросхемы FLEX 10KA имеют на контактах подтягивающие clamp диоды для 3,3В PCI совместимости.
Архитектура FLEX 10K поддерживает MultiVolt I/O интерфейс, который позволяет микросхемам FLEX 10K в любых корпусах взаимодействовать с системами с различным напряжением питания. Микросхемы имеют наборы контактов питания для внутреннего ядра и входных буферов (VCCINT) и для выходных драйверов (VCCIO).
При синтезе конечных автоматов на FLEX10K входные буферы ПЛИС могут использоватьтся в качестве элементов памяти конечных автоматов. Конечные автоматы типа Мили, допускающие такую реализацию, получили название автоматов класса E, а конечные автоматы типа Мура — автоматов класса F. Такой подход позволяет уменьшить число используемых макроячеек ПЛИС, в среднем, в 3,5 раза, а для отдельных реализаций — в 8–9 раз.

Рис. 18 Функциональная схема элемента ввода – вывода
Отличительной особенностью семейства FLEX 10K является наличие модулей памяти общей емкостью до 24 кбит, использование которой не ведет к уменьшению доступных разработчику логических ресурсов (логических элементов). Каждый блок памяти (рис.19) представляет собой ОЗУ емкостью 2048 (4096) бит и состоит из локальной матрицы соединений, собственно модуля памяти, синхронных буферных регистров, а также программируемых мультиплексоров.
Сигналы на вход локальной матрицы соединений блока памяти поступают со строки глобальной матрицы соединений . Тактовые и управляющие сигналы поступают с глобальной шины управляющих сигналов.
Выход блока памяти может быть скоммутирован как на строку, так и на столбец глобальной матрицы соединений.
Наличие синхронных буферных регистров и программируемых мультиплексоров позволяет конфигурировать блок памяти как ЗУ с организацией 256х8, 512х4, 1024х2, 2048х1. Кроме того, он может быть использован или как ПЗУ, или как FIFO.
Наличие блока памяти дает возможность табличной реализации таких элементов устройств ЦОС, как перемножители, АЛУ, сумматоры и т.п., имеющих быстродействие до 100 МГц (конечно при самых благоприятных условиях, реально быстродействие арифметических устройств, реализованных на базе блока памяти, составляет 10 – 50 МГц)
Все ПЛИС семейства FLEX10K совместимы по уровням с шиной PCI, имеют возможность как последовательной, так и параллельной загрузки, полностью поддерживают стандарт JTAG.
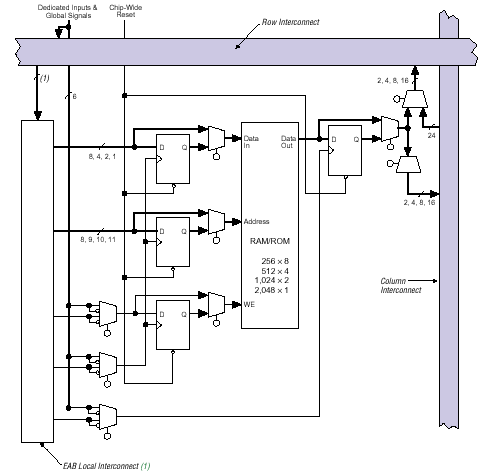
Рис. 19 Функциональная схема блока памяти
В течение первых лет развития ПЛИС они были представлены архитектурами CPLD и FPGA в «чистом» виде. Каждая из этих архитектур имеет свои достоинства и недостатки. Стремление к сочетанию достоинств CPLD и FPGA и рост уровня интеграции БИС/СБИС привели к появлению ПЛИС с комбинированной архитектурой. Класс ПЛИС с комбинированной архитектурой не имеет таких четких границ, как классы CPLD и FPGA, отличается большим разнообразием вариантов и различной степенью близости к тому или иному классическому типу ПЛИС. Не имеет он и общепринятого названия. Тем не менее, представляется целесообразным рассматривать ПЛИС с комбинированной архитектурой как отдельный класс, поскольку принадлежащие к нему схемы трудно квалифицировать как FPGA или CPLD, что подтверждается и разнобоем в названиях, используемых для таких схем различными фирмами.
Примером первых ПЛИС с комбинированной архитектурой могут служить микросхемы семейств APEX фирмы Altera (FLEX, Flexible Logic Element matriX).Архитектура APEX20K сочетает в себе как достоинства FPGA ПЛИС с их таблицами перекодировок, входящими в состав логического элемента, так и логику вычисления совершенных дизъюнктивных нормальных форм, характерную для ПЛИС CPLD , а также встроенные модули памяти (рис.20). Сходной архитектурой обладает и семейство Virtex фирмы Xilinx.
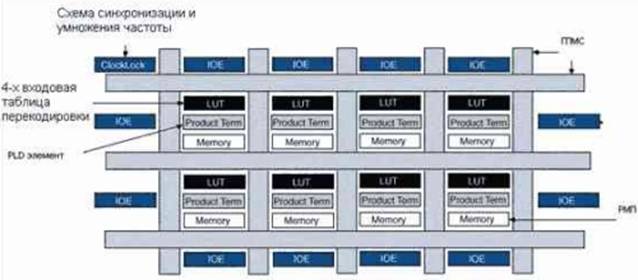
Рис. 20. Архитектура ПЛИС APEX20K.
Фактическое существование ПЛИС с комбинированной архитектурой и отсутствие для них общепринятого обобщающего названия вносят ощутимые неудобства в процесс составления классификации ПЛИС. Зачастую ПЛИС с комбинированной архитектурой представляются производителем под каким-либо конкретным именем, в котором не упоминаются ни CPLD, ни FPGA. Таких имен много, и на их основе не провести какую-либо классификацию. Общепризнанной окажется та терминология, которая исходит от крупнейших фирм-производителей микросхем этого типа. В то же время отнесение той или иной микросхемы в соответствующий раздел описания или справочной таблицы требует определенности в трактовке ее типа. Поэтому здесь наряду с узким применяется и широкое толкование термина FPGA. При этом выделяются «классические» FPGA с их канонической архитектурой, а ПЛИС комбинированной архитектуры при необходимости (главным образом, при описании справочных данных) относятся к FPGA в широком смысле этого понятия. Обоснованием такого подхода служит то, что в комбинированных архитектурах черты FPGA обычно проявляются более выражение, чем черты CPLD. Сказанное выше отображается на рис. 2, а объединением классических FPGA и ПЛИС с комбинированными архитектурами общим прямоугольником из штриховых линий.
Термин SOPC (System On Programmable Chip), т.е. «система на программируемом кристалле» относится к ПЛИС наибольшего уровня интеграции, содержащим сотни тысяч или даже миллионы эквивалентных вентилей [3]. Такой высокий уровень интеграции достигается только с помощью самых современных технологических процессов (малые топологические нормы проектирования, многослойность систем металлизации и т.д.). На основе прогрессивных технологических процессов обеспечивается одновременно высокий уровень интеграции и высокое быстродействие БИС/СБИС. В результате становится возможной интеграция на одном кристалле целой высокопроизводительной системы.
Классификация по уровню интеграции (рис. 2, б) дана кратко и отражает, главным образом, ситуацию последних годов — бурный рост уровня интеграции ПЛИС и выделение из них класса «системы на кристалле». В силу связи между уровнем интеграции и архитектурой, классификация не является строгой, и в ней имеется некоторое смешение двух признаков, однако она принята в показанном виде ради соответствия практически сложившимся понятиям.
ПЛИС с широким диапазоном изменения уровня интеграции (от простых до содержащих сотни тысяч вентилей) отнесены к «досистемным» в том смысле, что для них не рассматривались вопросы создания целых систем на одном кристалле. Класс SOPC делится на подклассы однородных и блочных систем на кристалле.
В однородных SOPC различные блоки системы реализуются одними и теми же аппаратными средствами, благодаря программируемости этих средств. При разработке систем используются так называемые «единицы интеллектуальной собственности» IP (Intellectual Properties), т. е. заранее реализованные параметризируемые мегафункции для создания тех или иных частей системы. Все блоки системы при этом являются полностью синтезируемыми, перемещаемыми и могут располагаться в разных областях кристалла. Создание IP стало важной сферой деятельности многих фирм, предлагающих на рынке широкий спектр разнообразных решений. Заметим, что приобретение IP обычно требует немалых затрат. Используя IP, проектировщик размещает на кристалле нужные ему блоки, которые будем называть soft-ядрами (Softcores).
Блочные SOPC имеют аппаратные ядра, т. е. специализированные области кристалла, выделенные для определенных функций. В этих областях создаются блоки неизменной структуры, спроектированные по методологии ASIC (как области типа БМК или схем со стандартными ячейками), оптимизированные для заданной функции и не имеющие средств ее программирования. Такие блоки будем называть hard-ядрами (Hardcores). Реализация функций специализированными аппаратными ядрами требует значительно меньшей площади кристалла в сравнении с реализациями на единых программируемых средствах и улучшает другие характеристики схемы, в первую очередь, быстродействие блоков, но уменьшает универсальность ПЛИС. Снижение универсальности сужает круг потребителей ПЛИС, т. е. тиражность их производства, что, в противовес факторам, удешевляющим схему, ведет к их удорожанию. Преобладание того или иного из указанных факторов зависит от конкретной ситуации.
Сейчас на рынке появилось большое число различных SOPC, и среди них наметились свои подклассы и проблемные ориентации. Не пытаясь детально классифицировать все варианты, целесообразно разделить блочные SOPC хотя бы на две группы: имеющие аппаратные ядра процессоров и не имеющие их. Первые представляют БИС/СБИС по-настоящему универсальные, т. к. содержат полный комплект блоков, характерных для микропроцессорной системы (имеется в виду цифровая часть системы, но следует отметить, что у некоторых SOPC есть и аналоговые блоки для ввода, предварительной обработки и последующей оцифровки аналоговых сигналов). Вторые специализированы и ориентированы на те или иные конкретные приложения. Но и здесь нужно отметить наличие у некоторых SOPC второго типа интерфейсных средств для сопряжения с процессором и ОЗУ различных типов, что облегчает построение целостных систем с применением таких SOPC.
Примером таких ПЛИС могут служить микросхемы семейств Cyclone III и Stratix III фирмы Altera.
Семейство Cyclone III сочетает высокую функциональность, низкое энергопотребление и низкую стоимость. Применение современного технологического процесса 65 нм и программного обеспечения Quartus II, позволяет снизить энергопотребление более чем на 50% по сравнению с предыдущим семейством Cyclone II. Основные ресурсы семейства Cyclone III представлены на рис. 21.
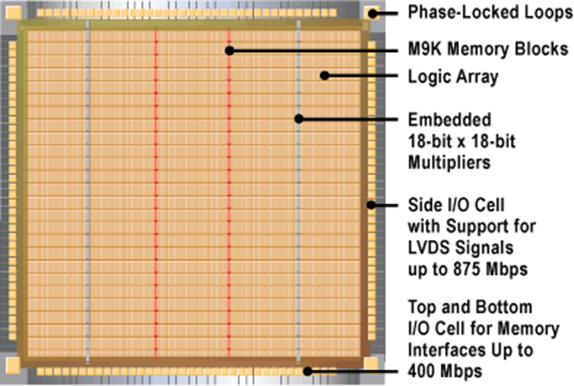
Рис. 21 Ресурсы CycloneIIIи их размещение на кристале
Объем ресурсов (до 120K ЛЭ, до 4Мбит встроенной памяти, до 288 встроенных умножителей, до 535 линий ввода-вывода) — говорит о высокой функциональности семейства. Архитектура Cyclone III поддерживает встраиваемый программный процессор NIOS II, производительностью свыше 160 DMIPS.
Схемы ФАПЧ (Phase-Locked Loops) используются для гибкого управления синхроимпульсами на системном уровне. Аналогичные схемные решения до этого применялись только в высококачественных дискретных устройствах PLL.
Устройства Cyclone III построены так, что они имеют на кристалле до 4 блоков PLL и до 10 системных цепей синхрочастот, для того, чтобы удовлетворить требованиям системы, проектируемой пользователем. Они могут использзоваться как для формирования сигналов синхронизации быстродействующих дифференциальных интерфейсов ввода – вывода, так и для тактирования общего назначения. Рис. 22 иллюстрирует особенности PLL для Cyclone III.
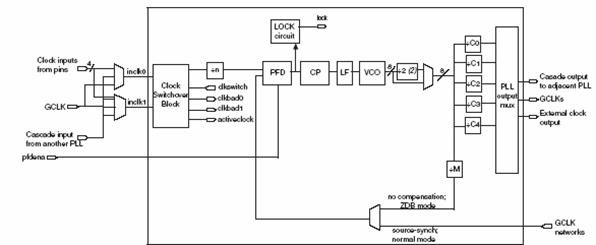
Рис. 22. PLL для Cyclone III
Блоки встроенной памяти M9K по 9 кбит могут использоваться для построения обычных ОЗУ, двухвходовых ОЗУ, ПЗУ, FIFO и регистров сдвига для реализации фильтров с БИХ и КИХ. Каждый блок может быть разбит на два в нужной пропорции. Суммарное число блоков M9K может быть до 432. Основные характеристики блока встроенной памяти M9K представлены на рис. 23.
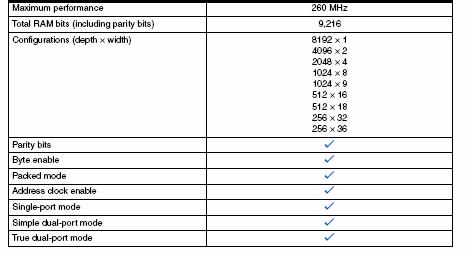
Рис. 23. Характеристики блока встроенной памяти M9K
Встроенные блоки умножителей 18х18 (рис. 24) являются эффективным средством для реализации функций цифровой обработки сигналов с тактовой частотой до 260 МГц. При необходимости каждый из них может быть разбит на два 9х9. наличие в их составе элементов регистровой памяти позволяет конвейеризировать вычисления.
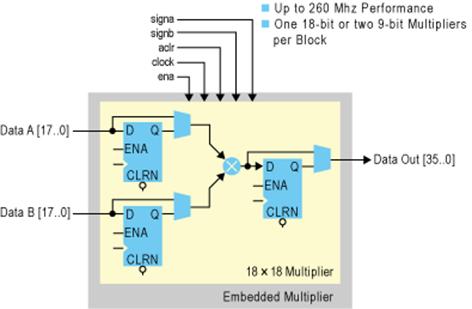
Рис. 24. Встроенный умножитель ПЛИС III
Логические блоки содержат по 16 логических элементов, связанных локальной матрицей соединений. В локальной шине управления две линии тактирования на блок. Суммарное число блоков может быть до 7443, а число логических элементов до 119088.
Логический элемент — самый маленький блок логики в архитектуре Cyclone III. Каждый LE (рис. 25), как и в предыдущих сериях устройств содержит четырехвходовую таблицу — LUT, которая является функциональным генератором, и может реализовать любую функцию от четырех переменных. Кроме того, каждый LE содержит программируемый регистр и цепочку переноса. Каждый LE передает свои сигналы по всем линиям связи: локальной линии, по строке, по столбцу, по цепочке LUT, по цепочке регистров, и по прямым связям.
Программируемый регистр каждого LE’s может быть сконфигурирован для работы в режиме D, T, JK, или SR. Каждый регистр имеет вход данных, асинхронные входы для сброса, входы синхрочастоты и входы разрешения синхрочастоты. Глобальные сигналы, входы ввода — вывода общего назначения, или любая внутренняя логика могут управлять синхрочастотой и сигналом сброса. Входами разрешения синхрочастоты и сброса могут управлять как входы ввода — вывода общего назначения так и внутренняя логика.
Каждый LE имеет три выхода, которые управляют локальный линией связи, линией связи по строке, и по столбцу. LUT или выход регистра могут управлять этими тремя выходами независимо. То есть LUT может управлять одним выходом, в то время как регистр управляет другим выходом. Эта особенность, называемая упаковкой регистра, улучшает использование устройства, потому что устройство может использовать регистр и LUT для различных несвязанных функций. Другой специальный упаковочный режим позволяет выходу регистра подавать сигналы назад в LUT. Это обеспечивает улучшение размещения проекта на кристалле.
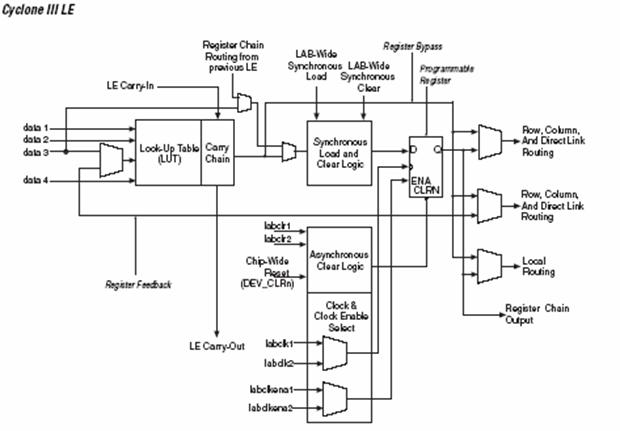
Рис.25. Логический элемент ПЛИС Cyclone III
Устройства Cyclone III поддерживают 12 стандартов ввода-вывода. В том числе формат передачи данных True-LVDS, для связи по интерфейсам LVDS, LVPECL, PCI Express для дифференциальных стандартов ввода — вывода, а также и для дифференциальных сигналов по HSTL и SSTL. Семейство Cyclone III имеет до 169 быстродействующих дифференциальных входов и 169 каналов дифференциальных выходов, в том числе до 77 каналов, оптимизированных для операций с 875-Mbps. На рис.26 изображены дифференциальные LVDS буферы, используемые как для передачи данных, так и для синхронизации.
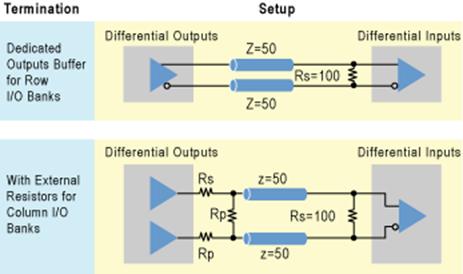
Рис.26. Дифференциальные LVDS буфферы.
Некоторые банки ввода/вывода содержат выделенную цепь для подключения внешней памяти. Эта цепь облегчает передачу данных внешним устройствам памяти, включая устройства DDR SDRAM и FCRAM. Максимальная скорость передачи данных достигает 266 Мбит/с (при тактовой частотой 133 МГц).
Устройства Cyclone способны работать с различными видами внешней памяти. Это новые стандарты памяти DDR SDRAM, FCRAM, и уже традиционные SDR SDRAM. Обмен данными осуществляется через выделенный интерфейс, который гарантирует быструю, надежную передачу данных со скоростями до 266 Мбит/с. При использовании имеющихся, оптимизированных функций контроллеров, разработчики могут реализовать интерфейсы DDR SDRAM и FCRAM в считанные минуты.
Устройства DDR SDRAM стали популярны благодаря низкому потреблению энергии, относительно небольшой стоимости и способности быстрой передачи данных. Передача данных происходит по обоим фронтам тактового сигнала, максимально увеличивая скорость передачи данных и удваивая эффективность по сравнению с более медленной архитектурой SDR. Устройства DDR SDRAM проникли на рынок через компьютерную область и теперь широко используются в широком диапазоне применений, от сетевых и коммуникационных приложений до домашних развлекательных приложений.
Устройства FCRAM похожие на SRAM устройства с малой задержкой, основанные на той же архитектуре, что и SRAM. Подобно SDRAM, устройства FCRAM поддерживают передачу данных по обоим фронтам системного тактового сигнала. Большая производительность этих устройств напрямую связана с собственными конвейерными и предзарядными операциями, которые существенно снижают время доступа по сравнению с архитектурой SDRAM.
В быстродействующих цифровых проектах, из-за увеличенных системных скоростей и сокращению длительности фронтов синхросигналов, предъявляются повышенные требования к передаче сигналов без искажения формы. Проектировщики должны соответствующим образом согласовать как однопроводные линии связи, так и дифференциальные линии связи, чтобы избежать искажений сигналов при передаче. Традиционно, проектировщики используют резисторы согласования (терминирования), расположенные на печатной плате, для того, чтобы достигнуть надлежащего согласования сигнала. Однако, эти резисторы занимают существенное место на печатной плате и могут все же вызывать отражения сигнала. Эти отражения обычно происходят, когда резистор согласования находится слишком далеко от того места на линии передачи, где она заканчивается.
Технология терминирования в устройствах Cyclone III представляет собой размещенные на кристалле резисторы терминирования, которые могут образовывать схему последовательного, параллельного, и дифференциального терминирования и согласования импеданса драйвера. Соответствующий импеданс драйвера необходим для максимальной системной эффективности, так как он позволяет добиться сокращения отражений сигнала и улучшает форму сигнала при работе на длинную линию связи (как показано на рис. 26). Два внешних задающих резистора (Rup и Rdn) используются как опорные резисторы, для одного банка VCCIO. Резистор Rup — подтянут к питанию, связанному с VCCIO, а резистор Rdn — связан с GND. Технология терминирования контролирует значение этих двух опорных резисторов и использует полученное значение, чтобы корректировать внутреннюю схему терминирования к тому же самому импедансу, что показано на рис. 27.. Кроме того, схема технологии терминирования дает компенсацию по напряжению питания, температуре, и т.д. Эта схема непрерывно калибрует внутренние резисторы терминирования во время нормальной работы устройства. Технология терминирования поддерживает один тип стандарта ввода — вывода для одного банка ввода — вывода.

Рис. 26. Технология терминирования улучшает форму сигнала.
Терминирование на кристалле также освобождает место на печатной плате и упрощает конструирование печатной платы, минимизируя число внешних резисторов, которые должны быть размещены на плате, по сравнено с другими методами терминированияЧтобы обеспечивать постоянную калибровку внутренних значений резистора, технология терминирования использует два внешних эталонных резистора на каждый банк ввода — вывода и контролирует значение этих резисторов.
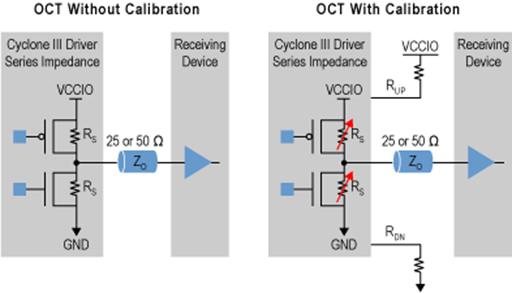
Рис. 27. Технология терминирования без и с калибровкой
2 Системные свойства микросхем программируемой логики
ПЛИС рассматриваются в настоящее время как наиболее перспективная элементная база для построения цифровой аппаратуры разнообразного назначения. Появляются и новые возможности реализации на программируемых микросхемах аналоговых и аналого-цифровых устройств. Перспективность ПЛИС базируется на ряде их достоинств, к числу которых можно отнести перечисленные ниже, справедливые для ПЛИС вообще, безотносительно к их конкретным разновидностям:
– универсальность и связанный с нею высокий спрос со стороны потребителей, что обеспечивает массовое производство.
– низкая стоимость, обусловленная массовым производством и высоким процентом выхода годных микросхем при их производстве вследствие достаточно регулярной структуры.
– высокое быстродействие и надежность как следствие реализации на базе передовых технологий и интеграции сложных устройств на одном кристалле.
– разнообразие конструктивного исполнения, поскольку обычно одни и те же кристаллы поставляются в разных корпусах.
– разнообразие в выборе напряжений питания и параметров сигналов ввода/вывода, а также режимов снижения мощности, что особенно важно для портативной аппаратуры с автономным питанием.
– наличие разнообразных, хорошо развитых и эффективных программных средств автоматизированного проектирования, малое время проектирования и отладки проектов, а также выхода продукции на рынок.
– простота модификации проектов на любых стадиях их разработки.
Для новейших вариантов ПЛИС с динамическим репрограммированием структур, кроме важных с общих позиций свойств, следует назвать и дополнительную специфическую черту: возможность построения на базе динамически репрограммируемых микросхем новых классов аппаратуры с многофункциональным использованием блоков.
2.1 Системы автоматизированного проектирования компании Mentor Graphics
Компания Mentor Graphics — один из признанных мировых лидеров в области САПР электроники. Фактически она входит в триаду законодателей мод в этой сфере. В кратком обзоре лишь упомянуты основные продукты Mentor Graphics для проектирования СБИС. Более подробно рассказать о них мы надеемся в последующих публикациях.
Спектр поставляемых компанией Mentor Graphics продуктов чрезвычайно широк — от средств проектирования СБИС, в том числе систем на кристалле (SoC) и систем на ПЛИС (FPSoC), до систем проектирования печатных плат, систем кабельных соединений и систем управления базами данных проектирования, интегрированных с PLM/PDM-системами предприятия. Основа стратегии Mentor Graphics — системный подход и концентрация усилий на наиболее перспективных секторах мирового рынка проектирования электронных систем. Отличительная особенность продуктов Mentor Graphics в том, что почти все они реализованы как на Unix-ориентированных рабочих станциях, так и на Intel-совместимых персональных компьютерах, что дает пользователю существенный выигрыш в стоимости аппаратной платформы и даже в производительности. В течение последних лет компания признана лидером и в области поддержки пользователей (Support Star Award).
Рассмотрим основные средства Mentor Graphics для системного и функционально-логического проектирования и верификации СБИС.
2.1.1 Системный уровень
Проектирование СБИС начинается с алгоритмического описания проекта на поведенческом уровне на языках C/C++, SystemC, System Verilog и т.д. Можно использовать IP-блоки системного уровня, в том числе модели MATLAB и Simulink. На этом этапе решают, как будет реализована система — чисто аппаратно либо программно-аппаратно. В последнем случае выбирается процессорное ядро (PowerPC, ARM, MIPS, и т.п.) и его периферийное окружение. Остановившись на конкретном ядре, уже на системном уровне можно начинать разработку встроенного программного обеспечения. Для этого предназначен комплекс таких инструментальных средств, как программно-отладочные среды XRAY Debugger и code/lab, компиляторы C/C++ Compilers, операционные системы реального времени VRTX и Nucleus. Компиляцию проекта на основе IP-блоков процессорного ядра и его периферийного окружения (контроллеры периферии, памяти, интерфейсы и т.п.) на уровне шинной архитектуры реализует пакет Platform Express. При необходимости уже на данном этапе можно подключать RTL-блоки, описанные на языках VHDL и Verilog — созданные пользователем либо взятые из IP-библиотек. Так, библиотека Inventra IP Mentor Graphics включает более 300 синтезируемых IP-блоков, в том числе устройства для телекоммуникационного оборудования (IEEE 802.11, Bluetooth, USB 2.0), шин передачи данных (CAN 2.0, PCI, PCMCI, UART), кодеров (Viterbi, Reed Solomon) и др. Для повышения скорости и точности верификации уже на системном уровне можно использовать мощные системы аппаратной эмуляции VStation (технология Virtual Wires) или Celaro Pro. В этом случае часть блоков, описанных на C/C++, моделируется программно, а блоки RTL-уровня — аппаратно.
На этапе поведенческого моделирования решается и вопрос о включении аналоговых/смешанных/высокочастотных блоков в общий проект системы на кристалле. Проектирование таких блоков в составе SoC выделяется в отдельный тракт с объединением и глобальной верификацией проекта на последующих этапах. Для верификации на системном уровне предназначены пакеты ModelSim (цифровое моделирование на VHDL, Verilog, C/C++, SystemC, System Verilog, PSL Assertions) и Seamless CVE/C-Bridge — программно-аппаратная верификация (в том числе -на уровне транзакций) и С-моделирование. Существенно, что пакет Seamless анализирует производительность программно-аппаратной системы и определяет ее «узкие» места. Например, обнаружив, что программная реализация некоторых функций не обеспечивает требуемого быстродействия, можно изменить архитектуру системы, поддержав эти функции аппаратными средствами. Данная задача реализуется модулем Seamless ASAP.
2.1.2 Уровень регистровых передач
Верифицированные на поведенческом уровне С/С++-описания алгоритмов можно синтезировать непосредственно в RTL-ypo-вень с помощью пакета Precision С Synthesis. Его предваряет временное планирование реализации алгоритмов, генерация микроархитектуры и ее оптимизация с учетом существующих ограничений. При необходимости возможно поцикловое моделирование посредством пакета ModelSim. После выполнения этих процедур включается механизм синтеза RTL-кода. Отличительные особенности пакета Precision С — полностью автоматизированный процесс генерации RTL-кода на основе стандартного С/С++-описания и возможность определения микроархитектуры без промежуточных представлений проекта. Причем качество автоматического синтеза часто выше, чем при ручной кодировке. На уровне RTL-блоков весь проект компонуется с помощью системы HDL Designer. При этом используются макросы из собственной библиотеки HDL Designer, библиотеки Inventra IP компании Mentor Graphics, из IP-библиотек других поставщиков, а также модули, синтезированные с помощью Precision С или написанные вручную.
После полного определения цифровой части проекта на уровне RTL ее детально моделируют посредством программы ModelSim и верифицируют с помощью пакета Seamless CVE. При больших объемах проекта и необходимости исчерпывающей верификации в максимально короткий срок на этом этапе широко используются системы аппаратной эмуляции. Аналоговые, смешанные и ВЧ-блоки системы моделируют отдельно либо вместе с цифровой частью с помощью системы ADMS. При этом возможно иерархическое представление проекта с различной степенью детализации отдельных блоков. В качестве языков описания могут быть использованы Spice, С, C++, VHDL-AMS, VHDL, Verilog, Verilog-A. ADMS имеет также встроенную систему ускоренного динамического моделирования на транзисторном уровне Mach ТА, опцию для моделирования в ВЧ-диапазоне ADMS-RF и мощную встроенную библиотеку функциональных блоков на языке VHDL-AMS — ADVance CommLJb.
2.1.3 Вентильный уровень
После окончательной верификации цифровой системы на RTL-уровне проект может быть синтезирован в виде FPGA или ASIC. Синтез описания на уровне элементов библиотек изготовителей реализуют такие средства, как LeonardoSpectrum (ASIC/FPGA), продукт компании Synopsys Design Compiler (ASIC), системы Precision RTL Synthesis и Precision Physical Synthesis (FPGA). Отметим, что последний инструмент имеет встроенный статический временной анализатор.
Компания Mentor Graphics придает исключительное значение маршруту проектирования систем на ПЛИС (FPGA/FPSoC). Это связано с наблюдающейся в последнее время тенденцией роста числа проектов на FPGA и их снижения на ASIC (прогноз на 2003 год — 400 тыс. и 4 тыс., соответственно). Проектирование на FPGA становится более рентабельным даже для крупных партий изделий, поскольку позволяет существенно сократить и удешевить циклы как проектирования, так и изготовления. Поэтому специально для FPGA компания Mentor Graphics создала комплексный, включающий все основные инструменты проектирования, маршрут FPGA Advantage. Он полностью совместим с программными средствами изготовителей ПЛИС (Xilinx, Altera, Actel, Lattice, и др.) и поддерживает все IP-ядра для FPGA.
При прохождении проекта от RTL до вентильного уровня эквивалентность контролируется с помощью системы формальной верификации FormalPro. На этих же этапах используется комплекс средств тестирования и обеспечения контролепригодности DFT (Design-for-Test). Основные инструменты этого комплекса — система автоматической генерации и диагностического знализа тестов для СБИС с высоким процентом сканирования FastScan ATPG, программа автоматической генерации цепей граничного сканирования СБИС в соответствии со стандартом IEEE 1149.1 BSDArchitect, инструмент автоматической генерации структур самотестирования для СБИС со встроенной памятью MBISTArchitect, анализатор контролепригодности с автоматической генерацией встроенных структур самотестирования и встроенных тестов для СБИС с произвольной логикой LBISTArchitect и генератор встроенных структур компрессии тестов на основе запатентованной технологии Embedded Deterministic Test (EOT) TestKompress.
2.1.4 Заказное проектирование аналоговых и смешанных схем
Маршрут проектирования заказных аналого-цифровых СБИС включает все основные этапы проектирования — создание принципиальной схемы проекта, функциональную верификацию проекта, проектирование топологии ИС и ее физическую верификацию, в том числе экстракцию паразитных параметров. Все модули маршрута полностью совместимы между собой и базируются на стандартных промышленных форматах, что позволяет использовать их в любом сочетании со средствами проектирования других поставщиков. Поддерживается методология проектирования как полностью заказных схем, так и на базе стандартных ячеек. Общая схема проекта создается в среде Design Architect-IC, включающей редактор ввода принципиальной схемы, модуль генерации списка цепей в форматах SPICE, HSPICE или Verilog, модуль подготовки и настройки моделирования аналоговых и смешанных схем и визуализатор для просмотра результатов моделирования.
Функциональное моделирование выполняется с помощью уже упоминавшейся системы ADMS, которая базируется на платформах цифрового VHDL/Verilog-моделирования ModelSim и аналогового моделирования Eldo Analog Design Station. Основные преимущества последней — высокая производительность, большой допустимый объем проектов (500 тыс. транзисторов) и высокая точность. Наряду с классическим алгоритмом численного моделирования Newton-Raphson она использует более совершенные алгоритмы OSR и IEM, а также позволяет назначать различные алгоритмы моделирования разным блокам. Поддерживаются практически все модели MOS, биполярных и MESFET-транзисторов (BSIMSvS.x, BSIM4.2, EKV, Philips MM9, Mextram, VBIC, HICUM и т.д.).
2.1.5 Топологическое проектирование
По завершении функционального моделирования начинается проектирование топологии СБИС. Для этого предназначены пакеты 1C Station, ICassemble и AutoCells. 1C Station включает интерактивный редактор топологии ICgraph Basic, генератор топологии на основе электрической принципиальной схемы ICgraph SDL, параметрические генераторы цифровых ICdevice Digital и аналоговых ICdevice Analog ячеек. 1C Station может применяться как для проектирования топологии кристалла в целом, так и для проектирования отдельных ячеек.
Планирование, размещение, интерактивную и автоматическую трассировку аналоговых и аналого-цифровых блоков, а также всего кристалла в целом выполняет модуль ICassemble. Инструмент AutoCells предназначен для размещения и трассировки цифровых блоков. В качестве входных данных он может использовать файлы GDSII и LEF, а также net-листы в форматах Verilog, EDIF и DEF.
Проектирование топологии завершается этапом физической верификации и экстракции паразитных параметров. Для этого предназначена платформа Calibre — фактически промышленный стандарт в области верификации топологии СБИС. Она включает модуль контроля топологических проектных норм Calibre DRC, модуль проверки соответствия топологии и электрической схемы Calibre LVS, модуль интерактивной верификации ячеек и блоков, работающий непосредственно в среде топологического редактора — Calibre Interactive, модуль визуализации результатов верификации и отладки Calibre RVE/QDB, модуль экстракции паразитных параметров для ячеек, блоков и кристаллов Calibre xRC. Последний поддерживает 30-экстракцию в форматах «сосредоточенный-С», «распределенный-СС», «распределен-ный-RC», «распределенный-RCC SPICE». Результаты экстракции могут быть использованы для более точного моделирования с учетом реальных физических параметров и соответствующей модификации схемы проекта.
При проектировании топологии глубокосубмикронных СБИС не обойтись без соответствующих методов коррекции маски (RET) для устранения эффектов искажения в субмикронном диапазоне. Эти функции реализованы с помощью модулей Calibre OPC и Calibre PCM.
В целом можно констатировать, что продукты компании Mentor Graphics, к проектированию СБИС, позволяют решать сколь угодно сложные задачи. Все они интегрированы в сквозной маршрут, верифицированный и поддерживаемый множеством технологических библиотек от ведущих изготовителей СБИС (UMC, TSMC, Chartered, IBM, STMicroelectronics, AMS и др.). Все продукты Mentor Graphics основаны на общепринятых стандартах, а поэтому легко интегрируются в маршруты проектирования других поставщиков. Отдельные пакеты, например Calibre, Seamless, ModelSim, TestKompress, занимают доминирующие позиции на мировом рынке. На российском рынке продукция Mentor Graphics достаточно широко используется с 1991 года.
2.2 Системы автоматизированного проектирования MAX+PLUS II и Quartus II
При работе с микросхемами программируемой логики основным инструментом является САПР. Фирма Altera предлагает две САПР MAX+PLUS II и Quartus II. Каждая САПР поддерживает все этапы проектирования: ввод проекта, компиляция, верификация и программирование. Каждая САПР имеет Tutorial (самоучитель), который устанавливается при инсталяции пакета. Tutorial состоит из занятий, в ходе которых проходится весь цикл проектирования от ввода проекта до программирования микросхем. При инсталяции также устанавливаюся файлы, описывающие проект так, что в ходе изучения Tutorial можно пропускать отдельные занятия и использовать готовые файлы. Например, можно пропустить «Ввод проекта» и перейти к «Компиляции» проекта, используя готовые файлы. Перевод Tutorial можно найти в книге [4].
САПР MAX+PLUS II является более простой в освоении по сравнению с Quartus II. Она поддерживает семейства MAX, FLEX и ACEX, которые содержат микросхемы с 5В питанием и количеством функциональных преобразователей от 32 до 4992 и имеет меньшее количество настроек. Эту САПР фирма Altera в настоящее время не развивает и рекомендует переходить на Quartus II. САПР Quartus II является основной. Фирма Altera активно ее развивает. Она поддерживает все новые семейства микросхем и обладает особенностями, которых нет в MAX+PLUS II.
САПР «MAX+plus II» представляет собой интегрированную среду для разработки цифровых устройств на базе программируемых логических интегральных схем (ПЛИС) фирмы Altera и обеспечивает выполнение всех этапов, необходимых для выпуска готовых изделий:
- создание проектов устройств;
- синтез структур и трассировку внутренних связей ПЛИС;
- подготовку данных для программирования или конфигурирования ПЛИС (компиляцию);
- верификацию проектов (функциональное моделирование и временной анализ);
- программирование или конфигурирование ПЛИС.
Наиболее полное фирменное описание системы «MAX+plus II» содержится в документе на сайте фирмы Altera, в который входит учебник («Tutorial»). На русском языке достаточно подробное описание системы «MAX+plus II» можно найти в работе [1]. Ниже приводятся в минимальном объёме сведения, необходимые для начального освоения технологии разработки цифровых устройств на ПЛИС фирмы Altera.
В состав пакета «MAX+plus II» входят следующие связанные между собой приложения, реализующие все перечисленные выше этапы разработки цифровых устройств на ПЛИС фирмы Altera:
Приложения для ввода проектов (редакторы проектов)
«Graphic Editor» – графический редактор, предназначенный для ввода проекта в виде схемы соединений символов элементов, извлекаемых из стандартных библиотек пакета либо из библиотеки пользователя.
«Waveform Editor» – редактор временных диаграмм (некоторые авторы называют это приложение сигнальным редактором), который выполняет двойную функцию: на этапе ввода обеспечивает ввод логики проекта в виде диаграмм (эпюр) состояний входов и выходов, а на этапе моделирования обеспечивает ввод диаграмм тестовых (эталонных) входных состояний моделируемого устройства и задание перечня тестируемых выходов.
«Text Editor» – текстовый редактор, предназначенный для создания и редактирования текстовых файлов, содержащих описание логики проекта на языке описания устройств AHDL (Altera Hardware Description Language) или на близких к нему языках типа VHDL, «Verilog». Для освоения языка AHDL можно рекомендовать [1, 2], а также статьи, опубликованные в ряде номеров журнала «Чипньюс».
«Symbol Editor» – символьный редактор, позволяющий редактировать существующие символы и создавать новые. Кстати, любой откомпилированный проект может быть свёрнут в символ, помещён в библиотеку символов и использован как элемент в любом другом проекте.
«Floorplan Editor» – редактор связей (поуровневый планировщик), который на плане расположения основных логических элементов позволяет вручную распределять выводы ПЛИС (закреплять выводы за конкретными входными и выходными сигналами) и перераспределять некоторые внутренние ресурсы ПЛИС.
Приложения «MAX+plus II Compiler»
Это приложения, входящие в пакет компилятора и предназначенные для синтеза структуры, трассировки связей, проверки корректности проекта и локализации ошибок, формирования файлов программирования или конфигурирования ПЛИС:
«Netlist Extractor» – приложение, обеспечивающее извлечение списка соединений из исходного файла представления проекта, созданного при вводе проекта.
«Database Builder» – приложение, предназначенное для построения базы данных проекта.
«Logic Synthesizer» – приложение, обеспечивающее проверку корректности проекта по формальным правилам и синтез оптимальной структуры проекта.
«Partitioner» – приложение, обеспечивающее разбиение проекта на части в тех случаях, когда ресурсов одного кристалла (микросхемы) недостаточно для реализации проекта.
«Fitter» – трассировщик внутренних связей, обеспечивающий реализацию синтезированной структуры.
«SNF Extractor» – приложение, обеспечивающее извлечение параметров проекта, необходимых для функционального моделирования и временного анализа.
Приложения для верификации проектов
«Simulator» – приложение, которое совместно с редактором временных диаграмм предназначено для функционального моделирования проекта с целью проверки правильности логики его функционирования.
«Timing Analyzer» – приложение, обеспечивающее расчет временных задержек от каждого входа до каждого логически связанного с ним выхода.
Наконец, для программирования или конфигурирования ПЛИС используется приложение «MAX+plus II Programmer».
Программирование и перепрограммирование микросхем, имеющих встроенную систему программирования (ISP), может осуществляться непосредственно в составе конечного изделия через специальный кабель, подключаемый либо к LPT-порту (Byte Blaster), либо к COM-порту (Bit Blaster) компьютера и технологического 10-контактного соединителя интерфейса JTAG, устанавливаемого на плате изделия. Схемы кабелей можно найти на сайте фирмы «Альтера»
Если на плате изделия устанавливается несколько ПЛИС со встроенными системами программирования, то все они могут программироваться через один технологический разъём. Для этой цели приложение «Programmer» имеет режим «Multi-Device» (к сожалению, бесплатные версии пакета этот режим не поддерживают). Схемы подключения ПЛИС к интерфейсу JTAG приводятся в документации на «Bit Blaster» и «Byte Blaster». Для программирования остальных микросхем необходимо дополнительно использовать внешний программатор, который также может подключаться к COM- или LPT-порту.
Сервисные приложения
В состав САПР, кроме того, входят три сервисных приложения:
«Design Doctor» – приложение, предназначенное для проверки корректности проекта с использованием эмпирических правил.
«Message Processor» – процессор сообщений, обеспечивающий обработку, вывод на отображение и локализацию (указание места в проекте, к которому оно относится) сообщений трёх типов: сообщений об ошибках («Error»), предупреждений («Warning») и информационных сообщений («Info»). Причину вывода того или иного сообщения можно выяснить через опцию «Help on Message» процессора сообщений. При наличии сообщений об ошибках компиляция проекта невозможна до их полного устранения. При наличии предупреждений компиляция успешно завершается, однако наличие предупреждения свидетельствует об обнаружении проблемы, которая может привести к неверной работе устройства. Поэтому все предупреждения должны быть тщательно проанализированы с использованием «Help on Message», до выяснения причин их появления и последующего устранения этих причин (или игнорирования предупреждения, что иногда бывает возможно). Информационные сообщения нужно только принимать к сведению.
«Hierarhy Display» – приложение, обеспечивающее обзор иерархической структуры проекта, который может состоять из множества составленных в различных редакторах и свёрнутых в символы проектов более низких уровней, причём число уровней не ограничивается. Основной проект (проект самого верхнего уровня) должен быть создан в графическом редакторе (если проект имеет только один уровень иерархии, то он может быть создан в любом редакторе).
Рабочие каталоги системы
Во время инсталляции пакета создаются два каталога: каталог \MAXPLUS2, который содержит все приложения и библиотеки пакета, и каталог \MAX2WORK, который содержит подкаталог \CHIPTRIP со всеми файлами учебного проекта, рассмотренного в руководстве («MAX+plus II Tutorial»), и ряд подкаталогов, используемых электронным справочником («MAX+plus II Help»). В этом же каталоге \MAX2WORK следует размещать и рабочие каталоги создаваемых проектов устройств.
Необходимость создания отдельных каталогов для каждого разрабатываемого проекта обусловлена тем, что в процессе разработки проекта системой MAX+plus II создаётся и поддерживается множество файлов, относящихся к текущему проекту. Прежде всего, это файл проекта («Project File»), название которого определяет название проекта в целом. Этот файл содержит основную логику и иерархию проекта, обрабатываемую компилятором. Кроме того, создаётся ряд вспомогательных файлов, связанных с проектом, но не являющихся частью логики проекта. Большая часть вспомогательных файлов создаётся и автоматически помещается в каталог проекта в процессе ввода и компиляции проекта. Это прежде всего файлы назначений и конфигурации (.ACF), файлы отчётов (.RPT), файлы данных для функционального моделирования и временного анализа (.SNF), файлы данных для программирования (.POF) и ряд других. Названия этих файлов всегда совпадают с названием проекта. Некоторые вспомогательные файлы создаются пользователем: например, для выполнения функционального моделирования создаётся файл (.SCF), содержащий описание начальных и текущих состояний входных сигналов (входов) и перечень выходов, для которых должны быть определены выходные сигналы. Поэтому перед началом работы над новым проектом следует создать рабочий каталог проекта, при этом имя каталога можно выбирать произвольно (т.е. имя каталога может не совпадать с именем файла проекта).
Одним из мировых лидеров по производству ПЛИС является фирма Altera. Для создания цифровых устройств на основе своих изделий Altera разработала специальную программную среду Quartus II. Эта среда позволяет:
- с помощью графического редактора ввести в память персонального компьютера электрическую схему;
- проверить и исправить ошибки;
- определить параметры и характеристики разработанного устройства;
- сформировать файл конфигурации для конкретной ПЛИС;
- загрузить этот файл в память интегральной схемы.
Quartus II — это следующий шаг в проектировании устройств с высокой степенью интеграции, включая разработку законченных систем на одном программируемом кристалле (System-on-a-programmable-chip (SOPC)).
Программное обеспечение Quartus II предоставляет полный цикл для создания высокопроизводительных систем на кристалле. Quartus II объединяет в себе проектирование, синтез, размещение элементов, трассировку соединений и верификацию, связь с системами проектирования других производителей.
Разработка систем на кристалле требует от разработчиков эффективной командной работы. Изменения в одной части проекта должно иметь минимальное влияние на других членов команды. Программное обеспечение Quartus II — это наиболее комплексная среда для разработки систем на кристалле SOPC, доступная в настоящее время. Quartus II включает в себя блочный метод разработки LogicLock.
LogicLock
LogicLock — это новая блочная методология проектирования, доступная исключительно в программном обеспечении Quartus II. Quartus II совместно с LogicLock — единственное программное обеспечение для разработки устройств на основе программируемой логики, которое включает в себя блочную методологию проектирования как стандартную функцию. Это помогает увеличить эффективность работы разработчиков, снизить время проектирования и верификации. LogicLock позволяет проектировать и проверять каждый модуль отдельно. Разработчики могут объединять готовые модули в проект верхнего уровня, сохраняя производительность каждого модуля в процессе объединения. LogikLock снижает время разработки и верификации, поскольку каждый модуль оптимизируется только один раз.
NativeLink
NativeLink — позволяет осуществлять связь между средством разработки Quartus II и программным обеспечением других производителей. NativeLink позволяет средствам синтеза сторонних производителей преобразовывать свои примитивы напрямую в примитивы устройств Altera. Прямое преобразование сокращает время компиляции и освобождает от использования дополнительных библиотек трансляций преобразований, которые могут ограничить производительность, достигнутую средствами проектирования сторонних производителей. Процесс разработки NativeLink позволяет разработчикам использовать Quartus II для размещения элементов, а средства проектирования других производителей — для оптимизации стратегий синтеза.
PowerFit
Технология размещения элементов и трассировки соединений PowerFit в программном обеспечении Quartus II использует временные параметры, заданные разработчиком, для оптимального составления схемы и размещения логических элементов. Интеллектуальный алгоритм трассировки по временным параметрам в программном обеспечении Quartus II уделяет первостепенное внимание соединениям, критичным к временным параметрам. Критичные к временным параметрам соединения оптимизируются в первую очередь, для уменьшения задержек и достижения максимальной производительности (fMAX). Дальнейшее улучшение параметра fMAX достигается использованием новейшей архитектуры, такой как в семействе устройств Stratix. Эта передовая технология размещения элементов и трассировки соединений помогает пользователям программного обеспечения Quartus II достичь максимальной производительности, и обладает самым малым временем компиляции проекта среди подобных средств разработки.
Верификация
Проверка или верификация проекта может оказаться самой продолжительной стадией в процессе разработки высокопроизводительных систем на кристалле (SOPC). Однако, используя Quartus II, возможно сократить время верификации, поскольку это программное обеспечение обладает набором собственных средств верификации, интегрированных с последними средствами верификации сторонних фирм.
Анализ
Altera разработала два метода, для того, чтобы помочь разработчикам проанализировать состояние внутренних точек и входов/выходов устройства. Это отладочное средство SignalProbe и логический анализатор SignalTap. Технологии SignalTap и SignalProbe могут работать совместно со средствами синтеза сторонних производителей и не требуют внесения изменений в исходный HDL файл проекта.
SignalProbe
Доступная в последних версиях программного обеспечения Quartus II технология аппаратной отладки SignalProbe позволяет пользователям последовательно соединять внутренние точки устройства со свободными зарезервированными выводами для анализа с помощью осциллографа или логического анализатора. При использовании технологии SignalProbe сохраняются все временные параметры и межсоединения устройства.
SignalTap
Для многих разработчиков, которые используют корпуса BGA с большим количеством входов/выходов, верификация системного уровня занимает очень много времени и иногда сильно затруднена. Логический анализатор SignalTap производит верификацию, с помощью интеграции функциональности логического анализатора в программном обеспечении. SignalTap позволяет разработчикам собрать данные с любых внутренних точек и входов/выходов устройства в режиме реального времени при работе системы. Quartus II вставляет в проект мегафункцию, содержащую логический анализатор. Данные собираются и сохраняются в блоках встроенной памяти устройства и направляются в программное обеспечение Quartus II через загрузочный кабель. Разработчики также могут подать внутренние сигналы на выводы устройства для дальнейшего мониторинга. Логический анализатор SignalTap позволяет существенно снизить время верификации, что позволяет в более короткие сроки выпускать новые продукты.
PowerGauge
Программное обеспечение Quartus II включает технологию PowerGauge — первое интегрированное средство анализа энергопотребления. Средство анализа PowerGauge использует файлы, созданные в процессе моделирования для того, чтобы связать оценку потребления энергии с заданными параметрами устройства. Используя симулятор Quartus II или симуляторы сторонних производителей, интегрированный анализатор энергопотребления позволяет потребителям Altera установить и оптимизировать потребление энергии на более ранней стадии процесса разработки.
Программирование микросхем происходит непосредственно из системы проектирования.
Система Quartus II поддерживает разнообразные средства описания проекта: схемный ввод, описания проекта языками AHDL, VHDL или Verilog, также введен редактор блоков (Block Editor), графическое средство описания параметризируемых модулей.
Система Quartus II предоставляет разработчику широкие возможности по различным изменениям при компиляции проекта. Если изменения при очередной итерации проекта затронули не весь проект, а его небольшую часть, то в системе имеется возможность так называемой nSTEP-компиляции, чем достигается высокая эффективность размещения на кристалле, приводящая к высокой производительности конечного изделия.
В состав программного обеспечения Quartus II входит средство SOPC Builder, с помощью которого можно создавать системы на кристалле с использованием ядра Nios. Процессор для встроенных применений Nios оптимизирован для использования в ПЛИС Altera и построения систем на кристалле SOPC. Также в состав ПО Quartus II входит Си-компилятор GNUPro для ядра Nios.
Фирма Altera предлагает бесплатные версии САПР Quartus II Web Edition, которая поддерживает все этапы проектирования от ввода проекта до программирования.
Пакет Quartus II Web Edition является бесплатной версией начального уровня САПР Quartus II и позволяет выполнять проекты на базе большинства ПЛИС кристаллов.
По сравнению с системой MAX+PLUS II эта САПР обладает новыми, более мощными возможностями, соответствующими сложности и интеграции микросхем Cyclone, APEX, MAX II и Stratix. САПР Quartus II позволяет создавать цифровые устройства, содержащие несколько миллионов логических вентилей с преимуществами, которые до нее еще не встречались в системах проектирования. Система проектирования Quartus II использует функции, которые позволяют увеличить производительность, уменьшить время отладки, сократить цикл проектирования и упростить разработку.
Эти функции включают в себя следующее:
- логический анализ SignalTap;
- инкрементальная перекомпиляция;
- совместная разработка;
- объединение EDA инструментов NativeLink;
- многопроцессорная поддержка.
Высокая степень интеграции новых семейств ПЛИС повышает значимость высокоуровневых форм проектных описаний. Одним из основных элементов представления функционирования устройств становятся МЕГАФУНКЦИИ описания типовых схем средней и высокой интеграции.
Наибольший интерес могут представлять следующие мегафункции:
- Интерфейс с шиной PCI.
- Цифровая обработка сигналов (быстрое преобразование Фурье, цифровые фильтры и др.).
- Периферийные устройства (приемопередатчик 16450, контроллер прямого доступа к памяти 8237, контроллер прерываний 8259, коммуникационный интерфейс 8251 и др.).
Широкие возможности предоставляет LPM (библиотека параметризованных модулей). Функции библиотеки логические схемы (ОЗУ, счетчики, сумматоры, мультиплексоры, память и др.), размерность и особенности которых определяет сам пользователь.
Удобную работу с функциями и высокую наглядность отображения обеспечивает СХЕМНЫЙ (БЛОЧНЫЙ) РЕДАКТОР. Кроме изображения простых схем он позволяет формировать иерархическую структуру в виде блок-схемы, каждый «квадратик» которой, в свою очередь, может представлять собой сложный узел, описанный любым из перечисленных способов.
Для более компактного и быстрого описания нетиповых схем удобно использовать высокоуровневые ЯЗЫКИ ОПИСАНИЯ стандартные VHDL, Verilog HDL и схожий с ними AHDL, знакомый еще пользователям системы MAX+PLUS II. Конструкции языков позволяют описывать конечные автоматы, арифметические операции (сложение, вычитание, умножение, равенство), условные операции «если-то», таблицы истинности, булевы уравнения.
Quartus предоставляет пользователю различные возможности изменения алгоритма синтеза посредством опций компиляции, задаваемых через систему меню. Отметим основные возможности Quartus, имеющие принципиальное значение.
- nSTEP-компиляция. Сложные схемы с высокой степенью интеграции требуют, как правило, несколько циклов компиляции до получения конечных результатов. Однако, чем сложнее схема, тем больше времени занимает этот процесс. nSTEP-компиляция позволяет компилировать только ту часть проекта, которая была изменена после предыдущей итерации. Это не только сокращает сроки разработки изделия, но и сохраняет неизменными размещение на кристалле и временные характеристики остальной части схемы.
- CoreSyn Synthesis. При синтезе проекта компилятор анализирует логические функции и размещает их на кристалле в ресурсы соответствующей архитектуры (LUT, матричные ячейки или блоки памяти), чем достигается высокая производительность и плотность размещения на кристалле.
- Временной синтез. Перед компиляцией разработчик может задать некоторые временные параметры, которые он хочет получить в ПЛИС после проектирования. К таким параметрам относятся: задержка распространения сигнала Tpd, время срабатывания от тактового сигнала Tco, время установления Tsu, внутренняя и системная частоты.
Как и MAX+PLUS II, Quartus позволяет произвести функциональный и временной анализ готовой схемы посредством системы моделирования (симулятора).
Однако, наряду с ней в Quartus впервые включено мощнейшее средство тестирования схемы анализатор SignalTap, представляющий собой параметризованную мегафункцию, входящую в комплект стандартной поставки Quartus. SignalTap регистрирует состояния не только на контактах ПЛИС, но и во внутренних точках, заданных разработчиком, в реальном масштабе времени и заносит эту информацию в память ESB. Далее данные по-ступают в компьютер через коммуникационный кабель MasterBlaster и выводятся на экран в редакторе временных диаграмм (Waveform Editor) для просмотра, анализа и отладки схемы.
MasterBlaster обеспечивает аппаратный интерфейс между микросхемами новых семейств ПЛИС и компьютером и выполняет загрузку и анализ ПЛИС через шину USB со скоростью до 8 Мбит/с или последовательный порт RS-232 со скоростью до 115000 бит/с. MasterBlaster поддерживает все возможные напряжения для ПЛИС фирмы Altera (1,8, 2,5, 3,3 и 5,0 В). Анализатор SignalTap может работать также и через ByteBlasterMV.
Программный пакет DSP Builder позволяет разработчикам систем цифровой обработки сигналов использовать все возможности высокопроизводительного семейства Stratix III и недорогого семейства Cyclone III фирмы ALTERA.
Поддерживая богатую коллекцию интеллектуальной собственности DSP MegaCore фирмы ALTERA, новая версия также осуществляет поддержку программных продуктов Matlab 7 и Simulink 6, входящих в пакет MathWorks Release 14.
DSP Builder включает в себя IP ядро преобразователя цвет — интервал и пример разработки краевого детектора для двухмерной фильтрации, помогающих ускорить разработку проектов обработки изображений и видеосигналов с использованием программы Simulink.
Расширяя свою богатую коллекцию интеллектуальной собственности DSP IP для DSP Builder, ALTERA предоставляет богатый выбор оптимизированных под применение FPGA библиотек для задач фильтрации, преобразования и прямой коррекции ошибок.
Комбинация DSP Builder с мощным комплектом разработки Stratix III DSP фирмы ALTERA является хорошей основой для разработки FPGA сопроцессоров с целью увеличения производительности DSP систем.
Использование для цифровой обработки сигналов Stratix III FPGA позволяет обеспечить выполнение быстрого преобразования Фурье (FFT) за 1,2 мкс — лучший результат в отрасли — и реализацию фильтра с конечной импульсной характеристикой (FIR) на частоту более 300 МГц.
Кроме того, прямая коррекция ошибок, требуемая для вещательного беспроводного стандарта 802.16b, может быть реализована на самой простой микросхеме семейства Cyclone III с использованием IP ядер декодера Витерби и Рида-Соломона, входящих в DSP Builder, что гарантирует невысокую стоимость беспроводного оборудования для рынка недорогого оборудования.
Благодаря применению среды, ориентированной на использование алгоритмов, DSP Builder позволяет сократить цикл разработки DSP устройства и быстро получить его аппаратную реализацию.
DSP Builder может быть подключен к приложению SOPC Builder фирмы ALTERA для проектирования специализированных FPGA сопроцессоров, подключение которых к центральному процессору не вызовет тоже никаких трудностей, что, в свою очередь, уменьшит время разработки.
Новый Nios II встроенный программный процессор поддерживается DSP Builder благодаря связи с приложением SOPC Builder, входящим в программный пакет разработки Quartus II, который обеспечивает минимальную стоимость разработки для сложных «систем на программируемом кристалле» (SOPC) разработок.
Литература
- Антонов А.П. Язык описания цифровых устройств. ALTERA HDL. Практический курс.-М.: ИП Радио Софт, 2002.- 224.
- Бибило П.Н. Основы VHDL языка. Изд. Соломон-Р ,- М.: 2000.-200 с.
- Грушвицкий Р.И., Мурсаев А.Х., Угрюмов Е.П. Проектирование систем на микросхемах программируемой логики.-СПб.: БХВ-Петербург,2002.-608 с.
- Зобенко А. А., Филиппов А. С., Комолов Д. А., Мяльк Р. А.. Системы автоматизированного проектирования фирмы Altera MAX+plus II и Quartus II. Краткое описание и самоучитель. — издательство «РадиоСофт» · 2002 г. · 360 с.
- Стешенко В.Б. ПЛИС фирмы “ALTERA”: элементая база, система проектирования и языки описания аппаратуры.- М.: Издательский дом, ДОДЕКА — XXI ,- 2002.- 576 с.
- Исследование цифровых устройств на основе (ПЛИС) в среде Quartus II :
http://www.leso.sibsutis.ru/index.php?act=metod&target=metod_leso2_1
- Компания «ГАММА» :
http://www.icgamma.ru/linecard/altera/kits/quartus2
- «Инлайн Груп» — официальный дистрибьютор фирмы Xilinx :
http://www.plis.ru/page.php?id=12
- Сайт статей посвященный проектированию цифровых устройств :
http://www.iclothes.ru/State_3.html
- Сайт статей посвященный проектированию цифровых устройств :
http://www.iclothes.ru/State_7.html
- Лаборатория Параллельных информационных технологий :
http://www.parallel.ru/FPGA/cpld.html
Leave a Response »








































 можно рассматривать как семейство (по параметру
можно рассматривать как семейство (по параметру  ) решений задач достижения
) решений задач достижения  . Аналогичный смысл придается и множеству
. Аналогичный смысл придается и множеству 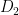 .
.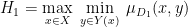 .
.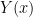 , зависящее от
, зависящее от  , есть множество возможных реакций (ответов) игрока 2 на выбор
, есть множество возможных реакций (ответов) игрока 2 на выбор 